Enterprise Information Management
Description
Data Management and the DMBOK
Data management is a long established practice in larger IT organizations. As a profession, it is represented by the Data Management Association (DAMA). DAMA developed and supported the Data Management Body of Knowledge (DMBOK), which is a primary influence on this Competency Category.
The Data Management Body of Knowledge (DMBOK)
DMBOK [DAMA 2010] is similar to other frameworks presented in this document (e.g., ITIL, COBIT, and PMBOK). It includes ten major functions:
-
Data Governance
-
Data Architecture Management
-
Data Development
-
Data Operations Management
-
Data Security Management
-
Reference and Master Data Management
-
Data Warehousing and Business Intelligence Management
-
Document and Content Management
-
Metadata Management
-
Data Quality Management
Attentive readers will notice some commonalities with general areas covered in this document: Governance, Architecture, Operations, and Security in particular. Data at scale is a significant problem area, and so the DMBOK provides a data-specific interpretation of these broader concerns, as well as more specialized topics.
We will not go through each of the DMBOK functions in order, but we will be addressing most of them throughout this Competency Category.
Data Architecture and Development
Data and Process
In order to understand data, we must understand how it is being used. We covered process management in Organization and Culture. Data is often contrasted with process, since processes take data inputs and produce data outputs. The fundamental difference between the two can be seen in the core computer science concepts of algorithms (process) and data structures. Data emerges, almost unavoidably, when processes are conceived and implemented. A process such as “Hire Employee” implies that there is an employee, and also a concept of “hire” with associated date and other circumstances. It may seem obvious, but data structures are surprisingly challenging to develop and gain consensus on.
The Ontology Problem
The boundaries of an entity are arbitrary, our selection of entity types is arbitrary, the distinction between entities, attributes, and relationships is arbitrary. [Kent 2012]
Preface to Kent's Data and Reality
Suppose you are discussing the concept of “customer” with a teammate. You seem to be having some difficulty understanding each other. (You are from support and they are from sales.) You begin to realize that you have two different definitions for the same word:
-
You believe that “customer” means someone who has bought something
-
They believe that “customer” includes sales leads
This is a classic issue in data management: when one term means two things. It can lead to serious confusion and technical difficulties if these misunderstandings affect how systems are built and operated. Because of this, it is critical to have rational and clear discussions about “what we mean”. In a startup driven by one or two visionary founders, perhaps little or no time is needed for this. The mental model of the problem domain may be powerfully understood by the founder, who controls the key architectural decisions. In this way, a startup can progress far with little formalized concern for data management.
But as a company scales, especially into multi-product operations, unspoken (tacit) understandings do not scale correspondingly. Team members will start to misunderstand each other unless definitions are established. This may well be needed regardless of whether data is being held in a database. The concept of a “controlled vocabulary” is, therefore, key to Enterprise Information Management.
In many areas of business, the industry defines the vocabulary. Retailers are clear on terms like “supplier”, “cost”, and “retail” (as in amount to be charged for the item; they do not favor the term “price” as it is ambiguous). The medical profession defines “patient”, “provider”, and so forth. However, in more flexible spaces, where a company may be creating its own business model, defining a controlled vocabulary may be essential. We see this even in books, which provide glossaries. Why does a book have a glossary, when dictionaries exist? Glossaries within specific texts are defining a controlled, or highly specific, vocabulary. General-purpose dictionaries may list multiple meanings for the same word, or not be very precise. By developing a glossary, the author can make the book more consistent and accurate.
There are techniques for developing controlled vocabularies in efficient and effective ways. The term “ontology engineering” is sometimes used [DeNicola & Missikoff 2016]. While specialists may debate the boundaries, another important practice is “conceptual data modeling”. All of these concepts (controlled vocabularies, glossaries, ontologies, conceptual data models) are independent of computers. But the initial development of controlled vocabulary is the first step towards automating the information with computers.
Data Modeling
An information system (e.g., database) is a model of a small, finite subset of the real world … We expect certain correspondences between constructs inside the information system and in the real world. We expect to have one record in the employee file for each person employed by the company. If an employee works in a certain department, we expect to find that department’s number in that employee’s record. [Kent 2012]
Data and Reality
Databases are the physical representation of information within computing systems. As we discussed above, the data contained within them corresponds to some “real world” concept we hold.
There are well-known techniques for translating concepts (e.g., controlled vocabularies) into technical database structures. The best known of these is relational data modeling.
Relational data modeling is often presented as having three layers:
-
Conceptual
-
Logical
-
Physical
The descriptions of the layers shown in Three Data Modeling Levels are typical.
Conceptual |
Independent of computing platform – no assumption of any database. Does include simple relationships. Does not include attributes. |
Logical |
Assumes a database, but not what kind. Includes more detailed relationships and attributes. Human-readable names. |
Physical |
Intended for a specific database platform (e.g., Oracle or MySQL). Computer-compatible names. Can be used to generate data definition scripts. |
A simple conceptual model might appear as shown in Conceptual Data Model.

The above model might be a fragment from a sales system. It shows that their are four major entities:
-
Customer
-
Invoice
-
Line Item
-
Product
This might be elaborated into a logical model; see Logical Data Model.
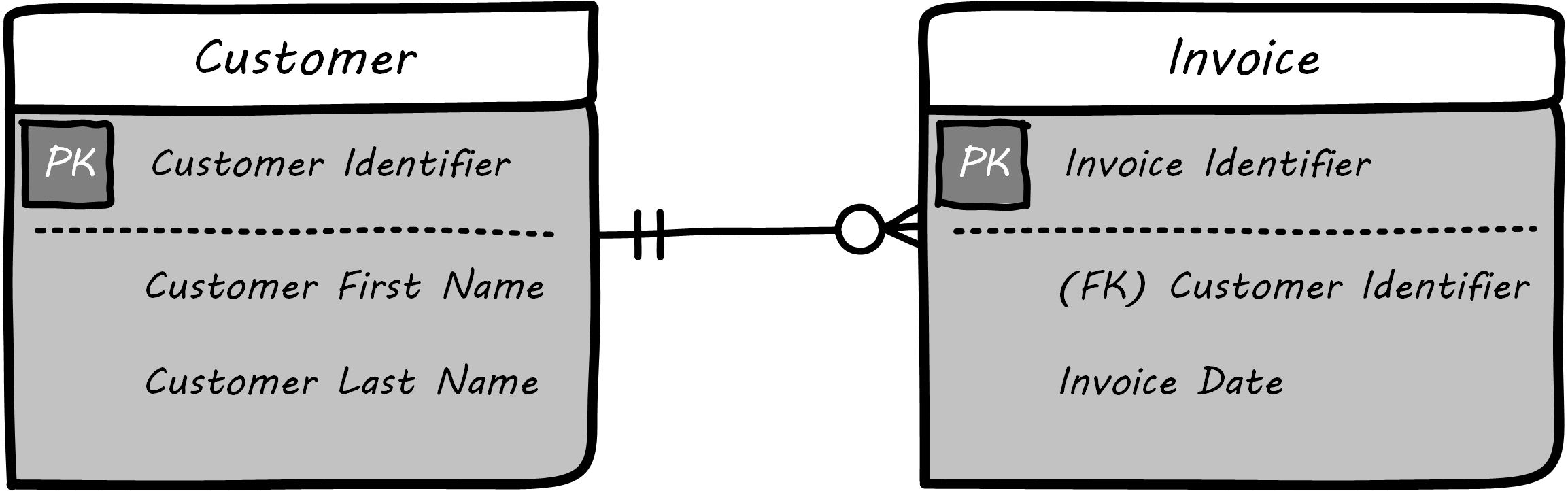
The logical model includes attributes (e.g., Customer First Name). The line between them has particular “adornments” representing a well-known data modeling notation called “crow’s foot”. In this case, the notation is stipulating that one customer may have zero to many invoices, but any invoice must have one and only one customer. Notice also that the entity and attribute names are human-readable.
Then, the logical model might be transformed into physical; see Physical Data Model.
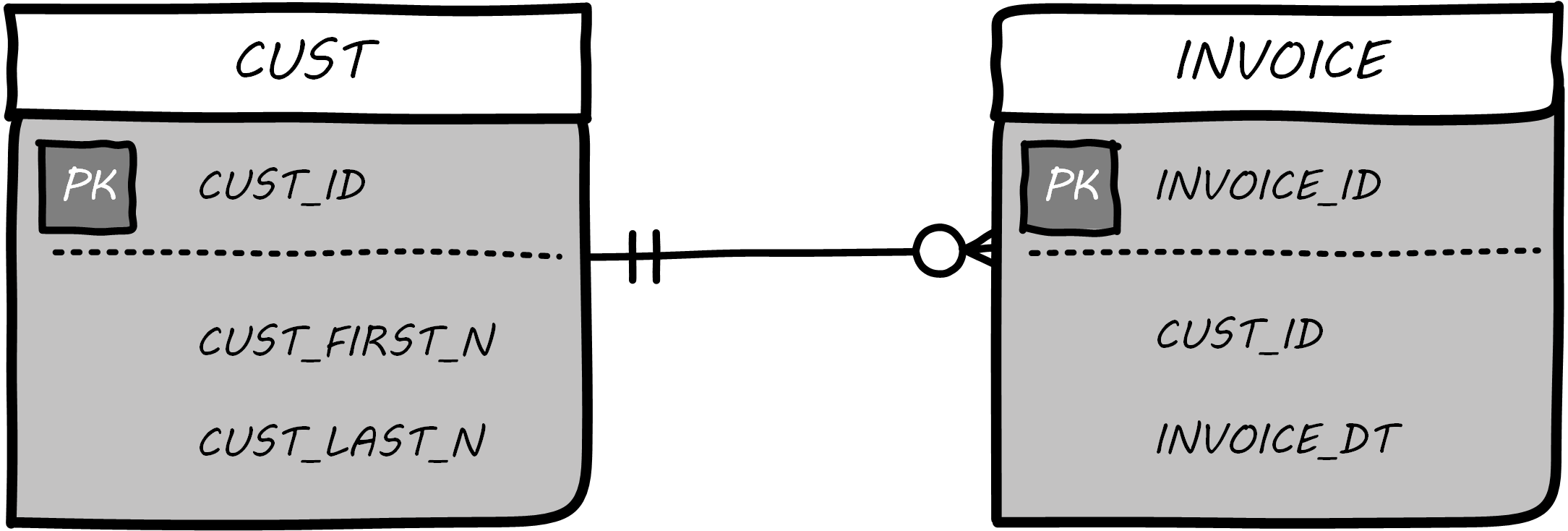
The names are no longer human-readable in full, nor do they have spaces. Common data types such as “name” and “date” have been replaced with brief codes (“N” and “DT”). In this form, the physical data model can be (in theory) translated to data definition language that can result in the creation of the necessary database tables.
Database Administration
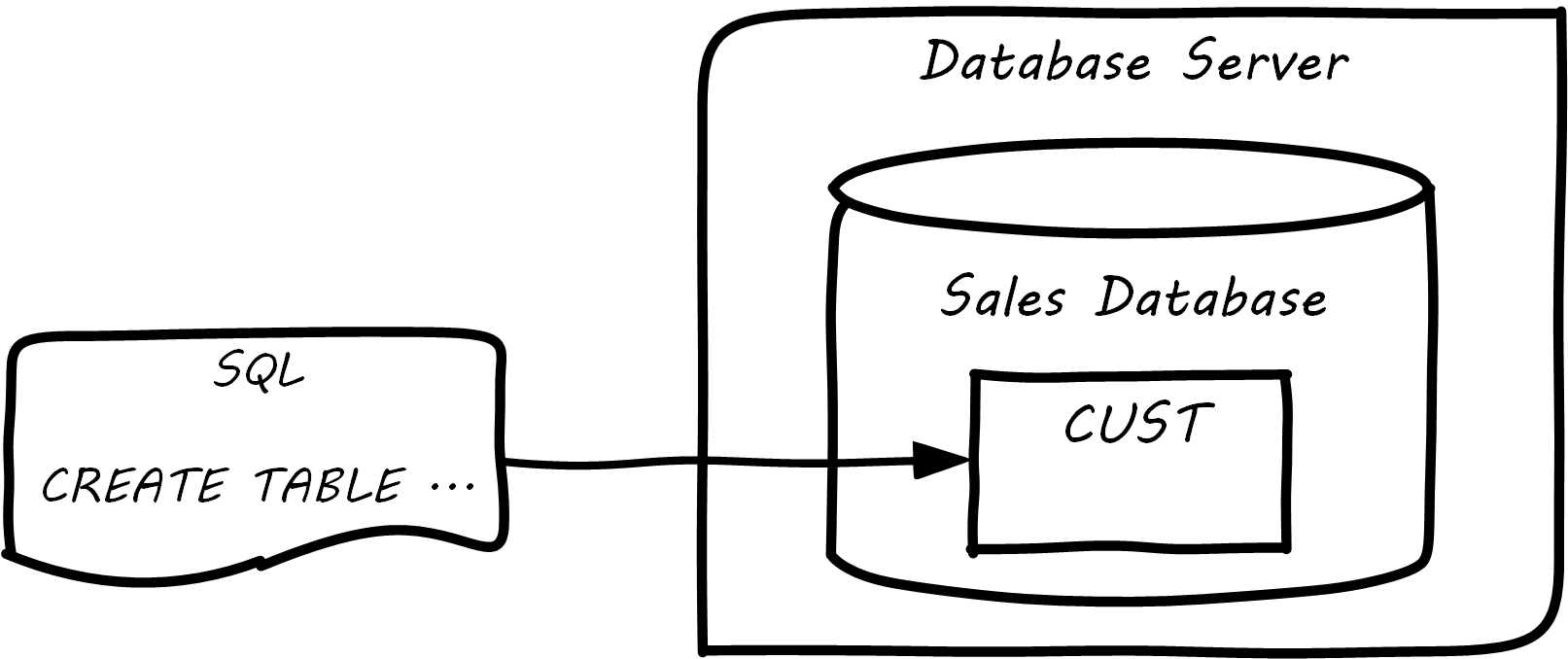
Continuing from above: the data modeling work might have been performed by a Data Architect or analyst, or a developer. Perhaps a pictorial representation is not even created (formal data modeling as above is less likely in a startup). But at some point (assuming a relational database) the following statement will be developed:
CREATE TABLE SALES.CUST (CUST_ID NUMBER, CUST_FIRST_N VARCHAR2(32), CUST_LAST_N VARCHAR2(32))
In the above SQL statement, the Customer entity has been finally represented as a series of encoded statements an Oracle database can understand, including specification of the data types needed to contain Customer Identifier (a number type) and the customer’s first and last names (a 32-character long string field, called “VARCHAR” in Oracle).
If a DBA issues that statement to the Oracle database, the table will be created. Once the structure is created, it can (within limits) hold any number of customers, in terms of knowing their first and last names and an ID number, which might or might not be assigned automatically by the system. (Of course, we would want many more attributes; e.g., Customer Address.)
| Notice that this database would only work for regions where customers have “first” and “last” names. This may not be true in all areas of the world; see Falsehoods Programmers Believe about Names. |
The Oracle software is installed on some node or machine and receives the statement. The database adds the table suggested; see Database Creates Table.
Further tables can easily be added in the same manner; see Multiple Tables in Database.
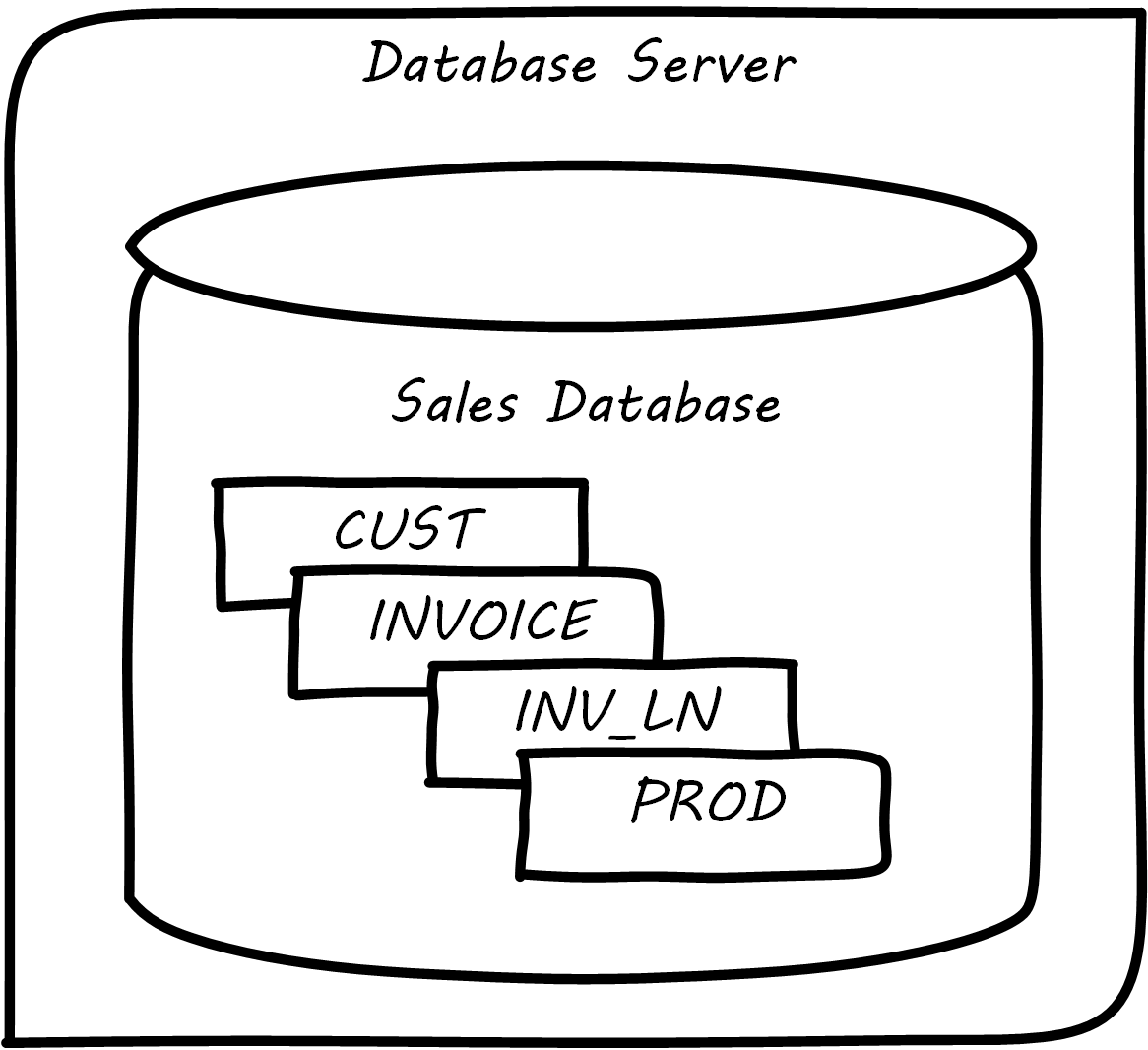
What is a database in this sense? The important point is that it is a common query space – you can ask for data from either the CUST, INVOICE, or Inventory LINe (INV_LN) table or ask the database to “join” them so you can see data from both. (This is how, for example, we would report on sales by customer.)
Patterns and Reference Architectures
Reference architectures and design patterns are examples of approaches that are known to work for solving certain problems. In other words, they are reusable solutions for commonly occurring scenarios. They apply to core software development, often suggesting particular class structures; see Gamma et al. 1995. However, the concept can also be applied to data and system architectures [Fowler 2002], [Betz 2011a]. David Hay [Hay 2011], and Len Silverston (Silverston 2001, Silverston 2001a, and Silverston 2008) have documented data models for a variety of industries.
Reference architectures also can provide guidance on data structures, as they often contain industry learnings. Examples are shown in Reference Architectures.
| Organization | Domain | Standard(s) |
|---|---|---|
TM Forum |
Telecommunications |
Frameworx, Enhanced Telecommunications Operating Model (ETOM), Telecom Application Map (TAM), Shared Information/Data Model (SID) |
Association for Retail Technology Standards (ARTS) |
Retail |
|
ACORD.org |
Insurance |
|
Banking Industry Architecture Network |
Banking |
|
The Open Group Exploration, Mining, Metals, and Minerals (EMMM™) Forum |
Exploration, Mining, and Minerals |
Exploration and Mining Business Reference Model [C135] |
The Open Group IT4IT Forum |
Information Technology Management |
IT4IT Standard [S220] |
Patterns and reference architectures can accelerate understanding, but they also can over-complicate solutions. Understanding and pragmatically applying them is the challenge. Certainly, various well-known problems such as customer address management have surprising complexity and can benefit from leveraging previous work.
The above description is brief and “classic” – the techniques shown here date back decades, and there are many other ways the same problem might be represented, analyzed, and solved. But in all cases in data management, the following questions must be answered:
-
What do we mean?
-
How do we represent it?
The classic model shown here has solved many large-scale business problems. But there are critical limitations. Continuing to expand one “monolithic” database does not work past a certain point, but fragmenting the data into multiple independent systems and data stores also has challenges; see CAP theorem. We will discuss these further as this Competency Category progresses.
Enterprise Information Management
The previous section was necessary but narrow. From those basic tools of defining controlled vocabularies and mapping them onto computing platforms, has come today’s digital economy and its exabytes of data.
The relational database as represented in the previous Competency Category can scale, as a single unit, to surprising volumes and complexity. Perhaps the most sophisticated and large-scale examples are seen in ERP (more detail on this in the Topics section). An ERP system can manage the supply chain, financials, human resources, and manufacturing operations for a Fortune 50 corporation, and itself constitute terabytes and tens of thousands of tables.
However, ERP vendors do not sell solutions for leading-edge Digital Transformation. They represent the commoditization phase of the innovation cycle. A digital go-to-market strategy cannot be based solely on them, as everyone has them. Competing in the market requires systems of greater originality and flexibility, and that usually means some commitment to either developing them with internal staff or partnering closely with someone who has the necessary skills. And as these unique systems scale up, a variety of concerns emerge, requiring specialized perspectives and practices.
The previous Competency Category gave us the basics of data storage. We turn to some of the emergent practices seen as Enterprise Information Management scales up:
-
Master data, data integration, and the System of Record
-
Reference data management
-
Data quality management
Data Integration and the “System of Record”
In the last section, we analyzed a business problem as a data model and created a simple database. Notice that if data is not in the database table, the database does not know about it. Therefore, if there is data held in other parts of the company, it must be loaded into the database before it can be combined with that database’s other data. This can also apply to data held by cloud providers.
Let us go back to our emergence model. Think about moving from one database to two.
In the example below, the CRM system is in the cloud, and data is also being imported from the product database; see Data Integrations.
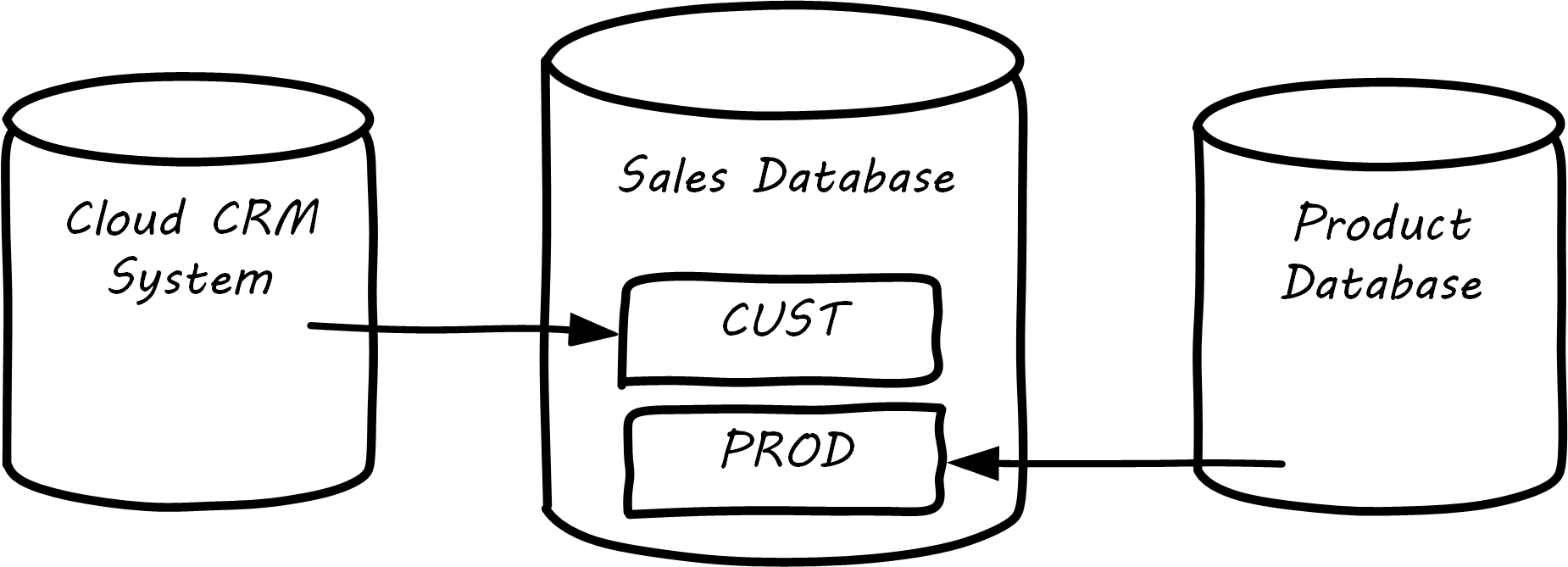
The process of identifying such remote data and loading it into a database to enable work to be done is known as “integration” and is a complex domain [Hohpe & Woolf 2003]. There are many ways data can be integrated, and industry views of what is “good practice” have changed over the years.
| Thinking in terms of the emergence model, you have likely been integrating data in various ways for some time. However, in a large, governed organization, you need to formalize your understandings and approach. |
Take Data Integrations and multiply it by several hundred times, and you will start to get an idea of the complexity of Enterprise Information Management at scale in the enterprise. How do we decide what data needs to flow where? What happens if we acquire another company and cannot simply move them over to our systems immediately? What department should properly own a given database? These and similar questions occupy data professionals worldwide.
As we see from the above picture, the same data may exist in multiple systems. Understanding what system is the “master” is critical. Product data should (in general) not flow from the sales database back into the product system. But what about sales information flowing from the sales database back to the CRM system? This might be helpful so that people using the CRM system understand how much business a customer represents.
The “System of Record” concept is widely used in data management, records management, and Enterprise Architecture to resolve these kinds of questions. It is often said that the System of Record is the “master” for the data in question, and sustaining the System of Record concept may also be called Master Data Management. In general, the System of Record represents data that is viewed as:
-
The most complete and accurate
-
Authoritative, in terms of resolving questions
-
Suitable for legal and regulatory purposes
-
The “source” for other systems to refer to
It is important to realize that the designation “System of Record” is a role that a given database (or system) plays with respect to some data. The “sales” database above might be the System of Record for invoices, but is not the System of Record for products or customers; see Enterprise Information Management.
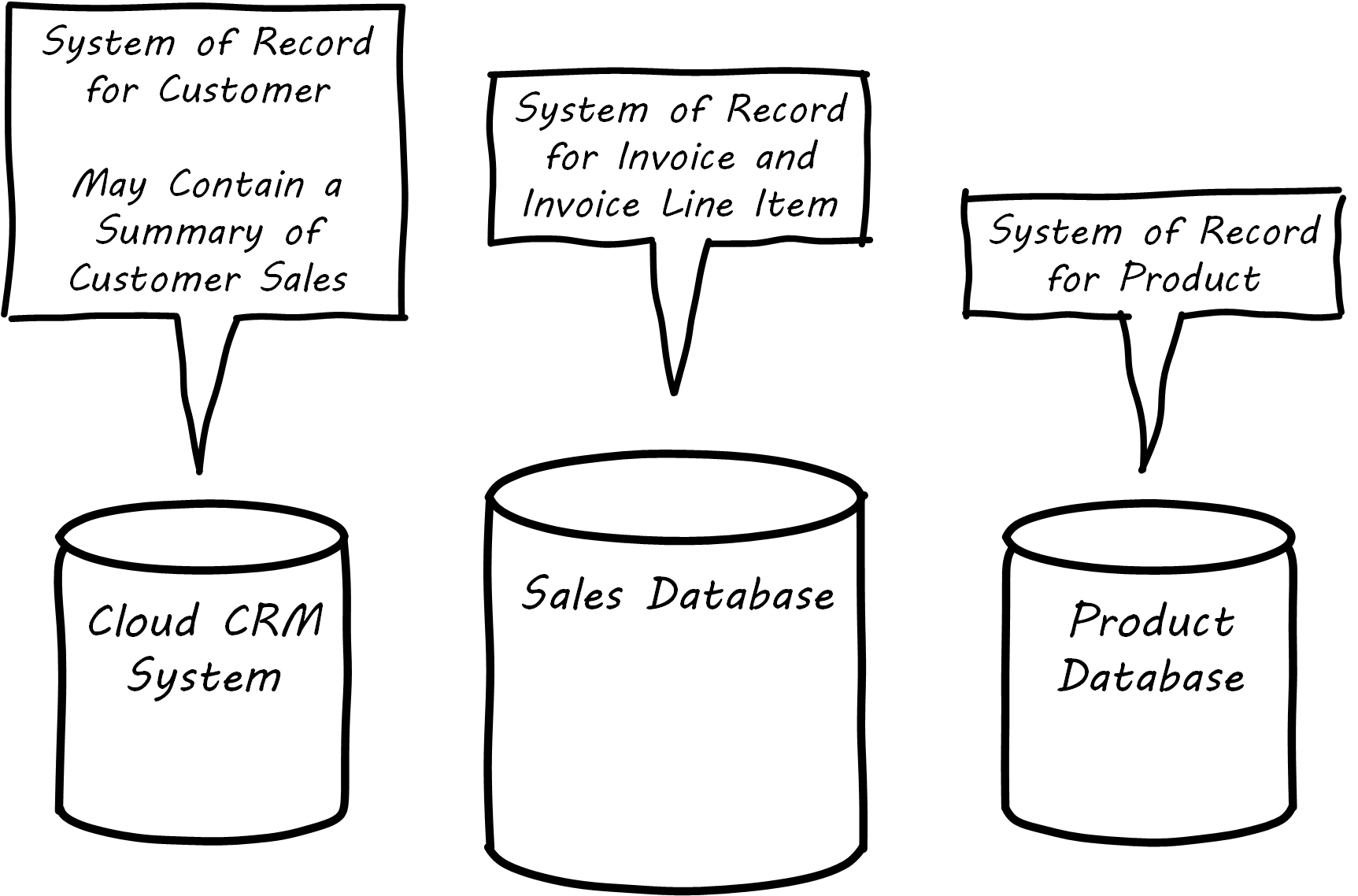
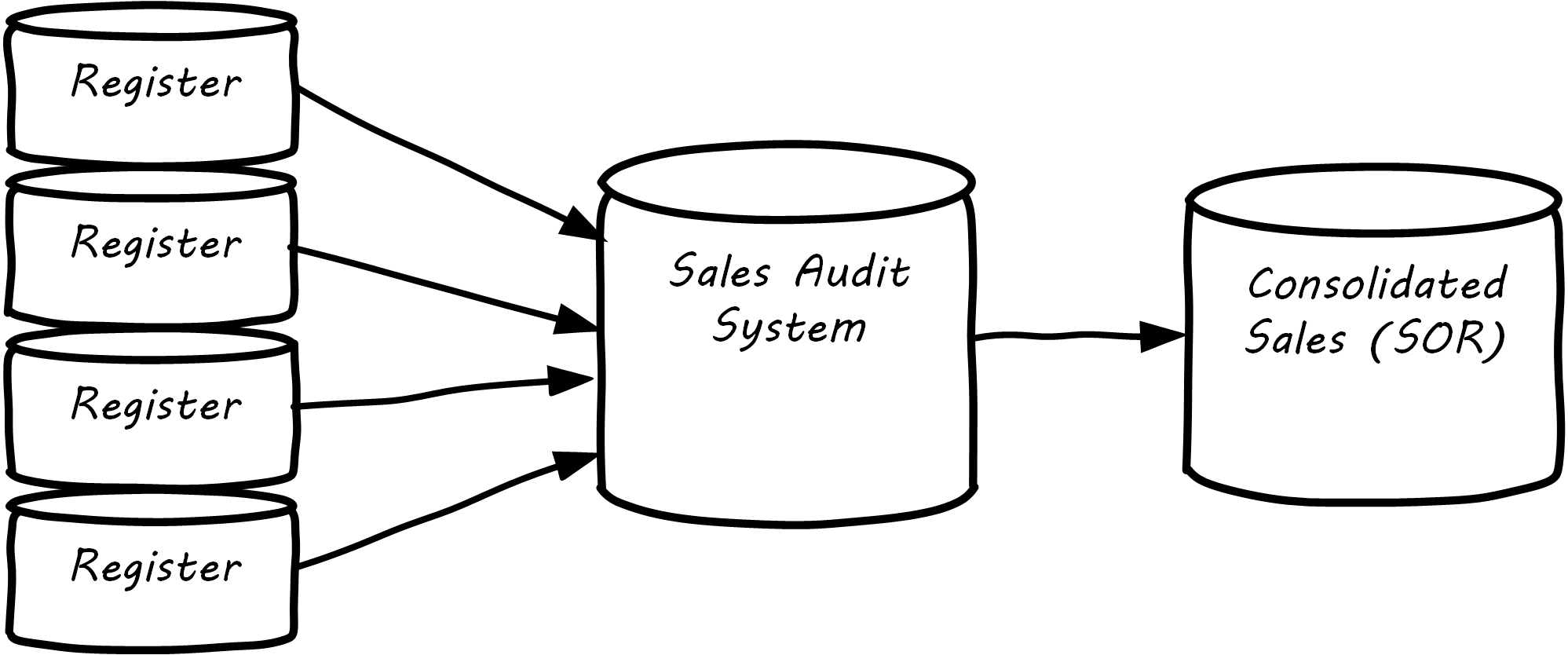
The System of Record is often the system of origin – the system where the data is first captured – but not always. In retail, sales transactions are not considered authoritative until they pass through the “Sales Audit System”, and so the System of Record for a transaction is not the cash register, which has a database in it; see Data Flow for Sales Information.
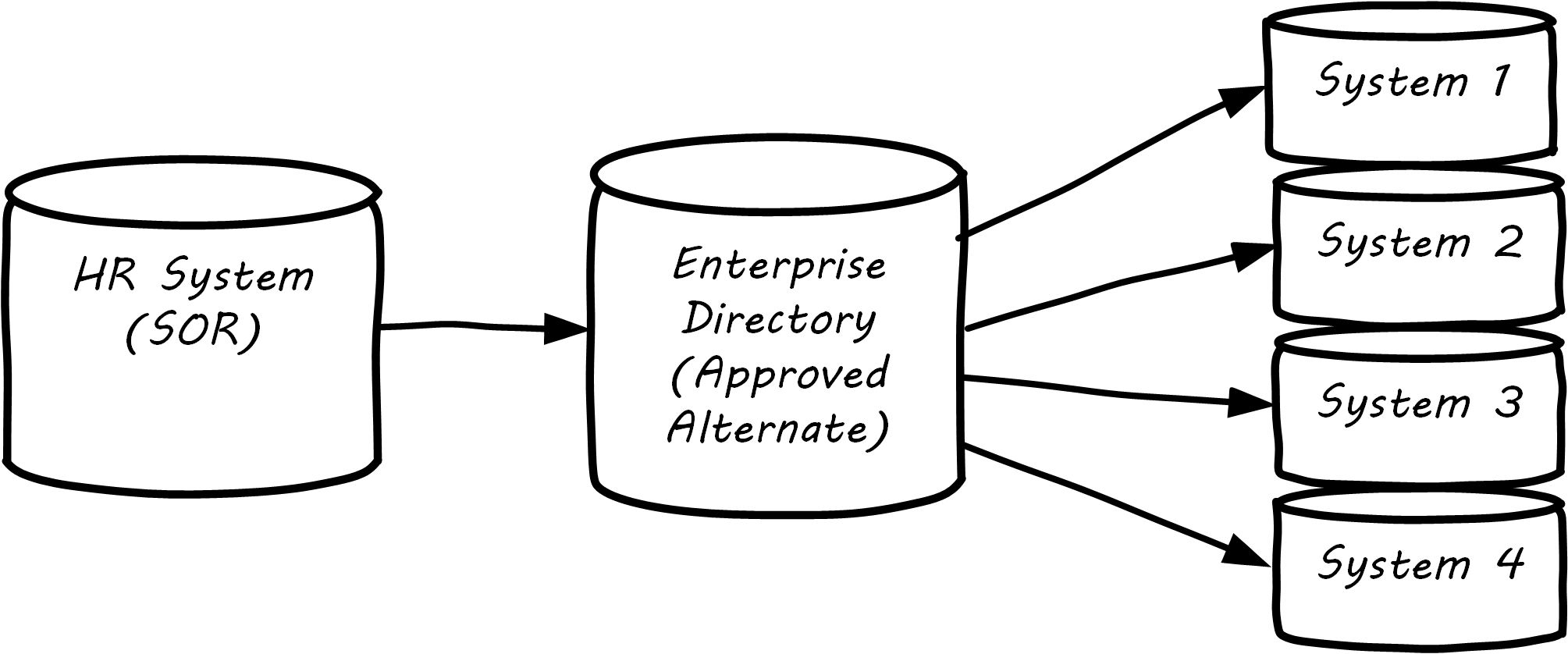
“System of Record” logically would be the first place to pull data from, but sometimes, due to performance or security concerns, data may be replicated into an alternate source better suited for distributing the data. A good example of this is a human resources system that feeds the corporate directory; the human resources system (e.g., Oracle HR, or Workday) is the actual System of Record for employee names and identifiers, but most people and other systems in the company will pull the data from the directory; e.g., Microsoft Exchange; see Data Flow for Human Resources Data.
Reference Data Management
Reference data is any kind of data that is used solely to categorize other data found in a database, or solely for relating data in a database to information beyond the boundaries of the enterprise. [Chisholm 2000]
Managing Reference Data
There are various ways to categorize data. Frequently, it is categorized by business process or functional area (sales, marketing, support, etc.). However, another important way to understand data is by its non-functional characteristics. Keep in mind that some data is transactional (e.g., Invoice and Invoice Line Item in the above example) and some is more persistent (Customer, Product).
When data is highly persistent and used primarily for categorizing across an enterprise, we may call it “reference” data. Classic examples of reference data include:
-
Geographic information (cities, states, zip codes)
-
Widely used “codes” in the business (medical insurance makes extensive use of these)
-
An organization’s chart of accounts
Reference data is among the first data to be shared between systems. It is often the basis for dimensions in analytic processing, which we cover in the next Competency Category.
Commercial Data
Data is not just an internal artifact of organizations. Data can be bought and sold on the open market like any other commodity. Marketing organizations frequently acquire contact information for email and other campaigns. Here are examples of commercial data available through market sources:
-
Stock prices (e.g., Bloomberg, Reuters)
-
Credit ratings (e.g., Trans-Union, Experian)
-
Known security issues
-
Technology products and availability dates
Other forms include:
-
Transactions of record (e.g., real estate)
-
Governmental actions (these may be nominally free from the government, but frequently are resold by vendors who make the data more accessible)
For a detailed examination of the privacy issues relating to commercial data, especially when governmental data is commercialized; see DHS 2006.
Data Quality
Human beings cannot make effective business decisions with flawed, incomplete, or misleading data.
Executing Data Quality Projects
We touched on quality management and continuous improvement in Organization and Culture. Data is an important subject for continuous improvement approaches. Sometimes, the best way to improve a process is to examine the data it is consuming and producing, and an entire field of data quality management has arisen.
Poor data quality costs the enterprise in many ways:
-
Customer dissatisfaction (“they lost my order/reservation”)
-
Increased support costs (30 minutes support operator time spent solving the problem)
-
Governance issues and regulatory risk (auditors and regulators often check data quality as evidence of compliance to controls and regulations)
-
Operational and supply chain issues
-
Poor business outcomes
The following activities are typically seen in data quality management (derived and paraphrased from DAMA 2010):
-
Identify measurable indicators of data quality
-
Establish a process for acting upon those indicators (what do we do if we see bad data?)
-
Actively monitor the quality
-
Fix both data quality exceptions, and their reasons for occurring
Data quality indicators may be automated (e.g., reports that identify exceptions) or manual (e.g., audits of specific records and comparison against what they are supposed to represent).
It is important to track trending over time so that the organization understands if progress is being made.
Enterprise Records Management
Not all enterprise information is stored in structured databases; in fact, most is not. (We will leave aside the issues of rich content such as audio, images, and video.) Content management is a major domain in and of itself, which shades into the general topic of knowledge management (to be covered in the Topics section). Here, we will focus on records management. As discussed above, businesses gained efficiency through converting paper records to digital forms. But we still see paper records to this day: loan applications, doctor’s forms, and more. If you have a car, you likely have an official paper title to it issued by a governmental authority. Also, we above defined the concept of a System of Record as an authoritative source. Think about the various kinds of data that might be needed in the case of disputes or legal matters:
-
Employee records
-
Sales records (purchase orders and invoices)
-
Contracts and other agreements
-
Key correspondence with customers (e.g., emails directing a stock broker to “buy”)
These can take the form of:
-
Paper documents in a file cabinet
-
Documents scanned into a document management system
-
Records in a database
In all cases, if they are “official” – if they represent the organization’s best and most true understanding of important facts – they can be called “records”.
This use of the word “records” is distinct from the idea of a “record” in a database. Official records are of particular interest to the company’s legal staff, regulators, and auditors. Records management is a professional practice, represented by the Association of Records Management Administrators (www.arma.org). Records management will remain important in digitally transforming enterprises, as lawyers, regulators, and auditors are not going away.
One of the critical operational aspects of records management is the concept of the retention schedule. It is not usually in an organization’s interest to maintain all data related to all things in perpetuity. Obviously, there is a cost to doing this. However, as storage costs continue to decrease, other reasons become more important. For example, data maintained by the company can be used against it in a lawsuit. For this reason, companies establish records management policies such as:
-
Human resources data is to be deleted seven years after the employee leaves the company
-
POS data is to be deleted three years after the transaction
-
Real estate records are to be deleted ten years after the property is sold or otherwise disposed of
This is not necessarily encouraging illegal behavior. Lawsuits can be frivolous, and can “go fishing” through a company’s data if a court orders it. A strict retention schedule that has demonstrated high adherence can be an important protection in the legal domain.
| If you or your company are involved in legal issues relating to the above, seek a lawyer. This discussion is not intended as legal advice. |
We will return to records management in the discussion below on e-discovery and cyberlaw.
Records management drives us to consider questions such as “who owns that data” and “who takes care of it”. This leads us to the concept of data governance.
Data Governance
This document views data governance as based in the fundamental principles of governance from Governance, Risk, Security, and Compliance:
-
Governance is distinct from management
-
Governance represents a control and feedback mechanism for the digital pipeline
-
Governance is particularly concerned with the external environment (markets, brands, channels, regulators, adversaries)
By applying these principles, we can keep the topic of “data governance” to a reasonable scope. As above, let us focus on the data aspects of:
-
Risk management, including security
-
Compliance
-
Policy
-
Assurance
Information-Related Risks
The biggest risk with information is unauthorized access, discussed previously as a security concern. Actual destruction, while possible, is also a concern; however, information can be duplicated readily to mitigate this. Other risks include regulatory and civil penalties for mis-handling, and operational risks (e.g., from bad data quality).
There is a wide variety of specific threats to data, leading to risk; for example:
-
Data theft (e.g., by targeted exploit)
-
Data leakage (i.e., unauthorized disclosure by insiders)
-
Data loss (e.g., by disaster and backup failure)
The standard risk and security approaches suggested in Governance, Risk, Security, and Compliance] are appropriate to all of these. There are particular technical solutions such as data leakage analysis that may figure in a controls strategy.
A valuable contribution to information management is a better understanding of the risks represented by data. We have discussed simple information sensitivity models (for example Public, Internal, Confidential, Restricted). However, a comprehensive information classification model must accommodate:
-
Basic sensitivity (e.g., confidential)
-
Ownership/stewardship (e.g., Senior Vice-President Human Resources, Human Resources/Information Services Director)
-
Regulatory aspects (e.g., SOX or HIPAA)
-
Records management (e.g., “Human Resources”, “Broker/Client Communications”, “Patient History”)
Beyond sensitivity, the regulatory aspects drive both regulatory and legal risks. For example, transmitting human resources data related to German citizens off German soil is illegal, by German law. (There are similar regulations at the European Union level.) But if German human resources data is not clearly understood for what it is, it may be transmitted illegally. Other countries have different regulations, but privacy is a key theme through many of them. The US HIPAA regulations are stringent in the area of US medical data. In order to thoroughly manage such risks, data stores should be tagged with the applicable regulations and the records type.
The broad topic of individuals' expectations for how data relating to them is stored and secured is called data privacy. It drives regulations, lawsuits, standards, and is a frequent topic of news coverage (e.g., when a mass data breach occurs). Bad data quality also presents risks as mentioned above. In fact, DeLuccia 2008 sees data quality as a kind of control (in the sense of risk mitigation).
E-discovery and Cyberlaw
Information systems and the data within them can be the subject of litigation, both civil and criminal. A criminal investigation may ensue after a security breach. Civil and regulatory actions may result from, for example, inappropriate behavior by the organization, such as failing to honor a contract. In some cases, records are placed under a “legal hold”. This means that (whether physical or digital) the records must be preserved. The US Federal Rules of Civil Procedure [National Court 2016] covers the discovery of information stored in computing systems. Successfully identifying the data in scope for the hold requires disciplined approaches to records management and data classification, as described above.
| Again, if you or your company are involved in legal issues relating to the above, seek a lawyer. This discussion is not intended as legal advice. |
Evidence of Notability
Information management is the basis of computing and IT. Its notability is evidenced in the existence of professional associations like the Data Management Association and the Information and Records Management Association, as well as the revenues of companies like Oracle and IBM for their data management products, and finally the broad career paths available for DBAs and data scientists.
Limitations
Data management, as a discipline concerned with the general question of information, is abstract and only arises as a formal focus of attention in larger organizations.
Related Topics