Monitoring and Telemetry
Description
Computers run in large data centers, where physical access to them is tightly controlled. Therefore, we need telemetry to manage them. The practice of collecting and initiating responses to telemetry is called monitoring.
Monitoring Techniques
Limoncelli et al. define monitoring as follows: “Monitoring is the primary way we gain visibility into the systems we run. It is the process of observing information about the state of things for use in both short-term and long-term decision-making” [Limoncelli et al. 2014].
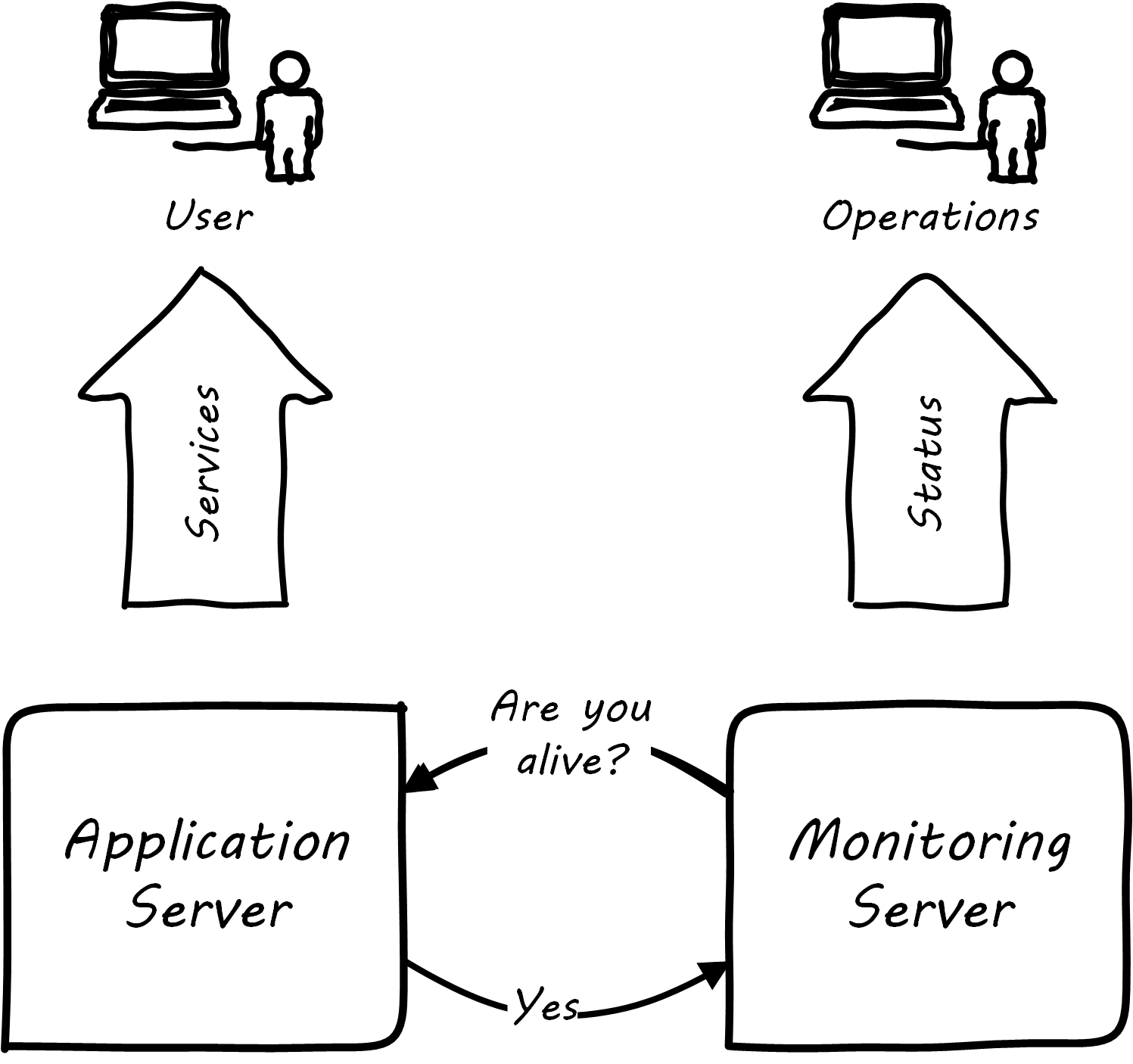
But how do we “observe” computing infrastructure? Monitoring tools are the software that watches the software (and systems more broadly).
A variety of techniques are used to monitor computing infrastructure. Typically these involve communication over a network with the device being managed. Often, the network traffic is on the same network carrying the primary traffic of the computers. Sometimes, however, there is a distinct “out-of-band” network for management traffic. A simple monitoring tool will interact on a regular basis with a computing node, perhaps by “pinging” it periodically, and will raise an alert if the node does not respond within an expected timeframe; see Simple Monitoring.
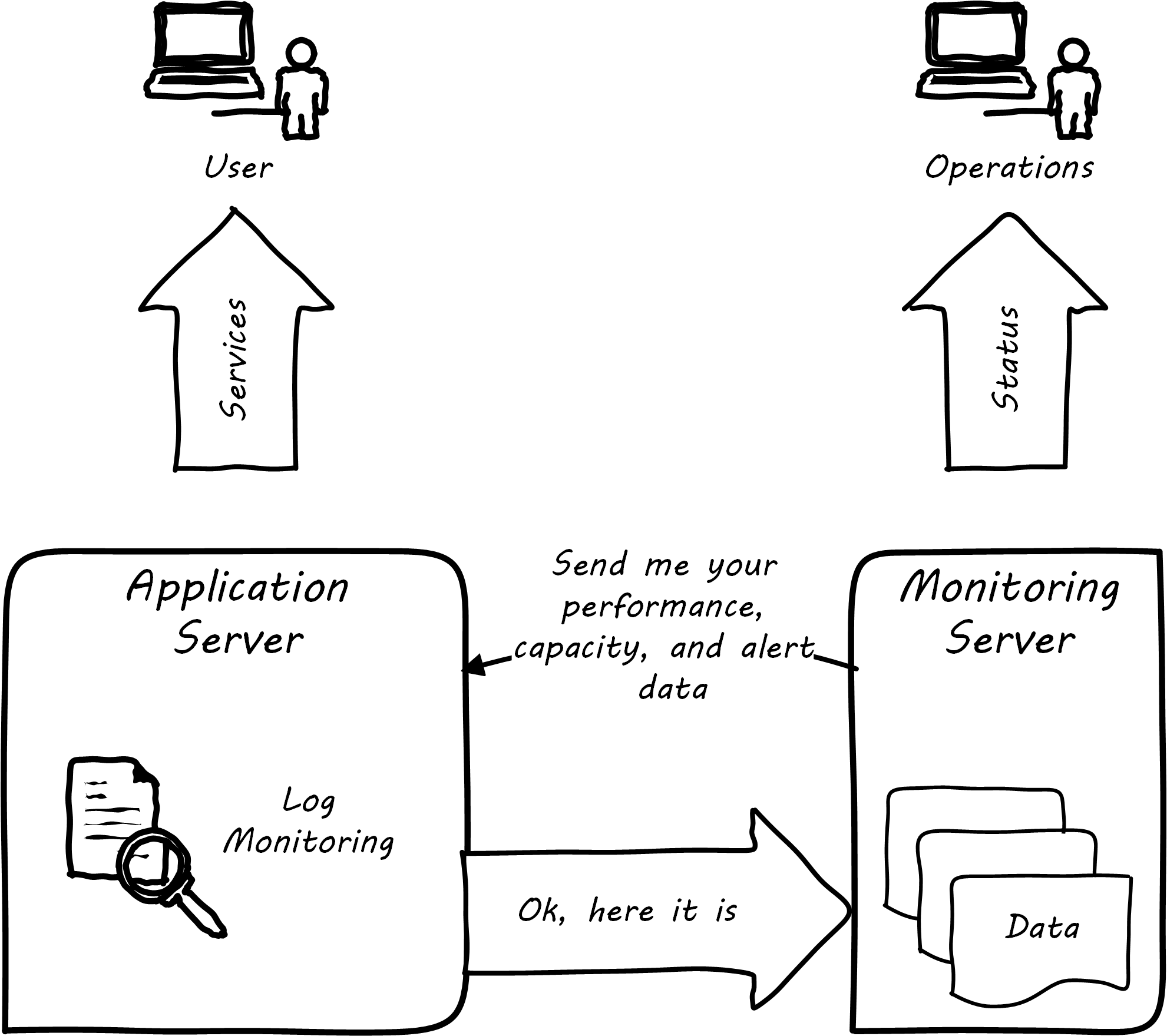
More broadly, these tools provide a variety of mechanisms for monitoring and controlling operational IT systems; they may monitor:
-
Computing processes and their return codes
-
Performance metrics (e.g., memory and CPU utilization)
-
Events raised through various channels
-
Network availability
-
Log file contents (searching the files for messages indicating problems)
-
A given component’s interactions with other elements in the IT infrastructure; this is the domain of application performance monitoring tools, which may use highly sophisticated techniques to trace transactions across components of distributed infrastructure; see also the OpenTracing standard
-
And more (see Extended Monitoring)
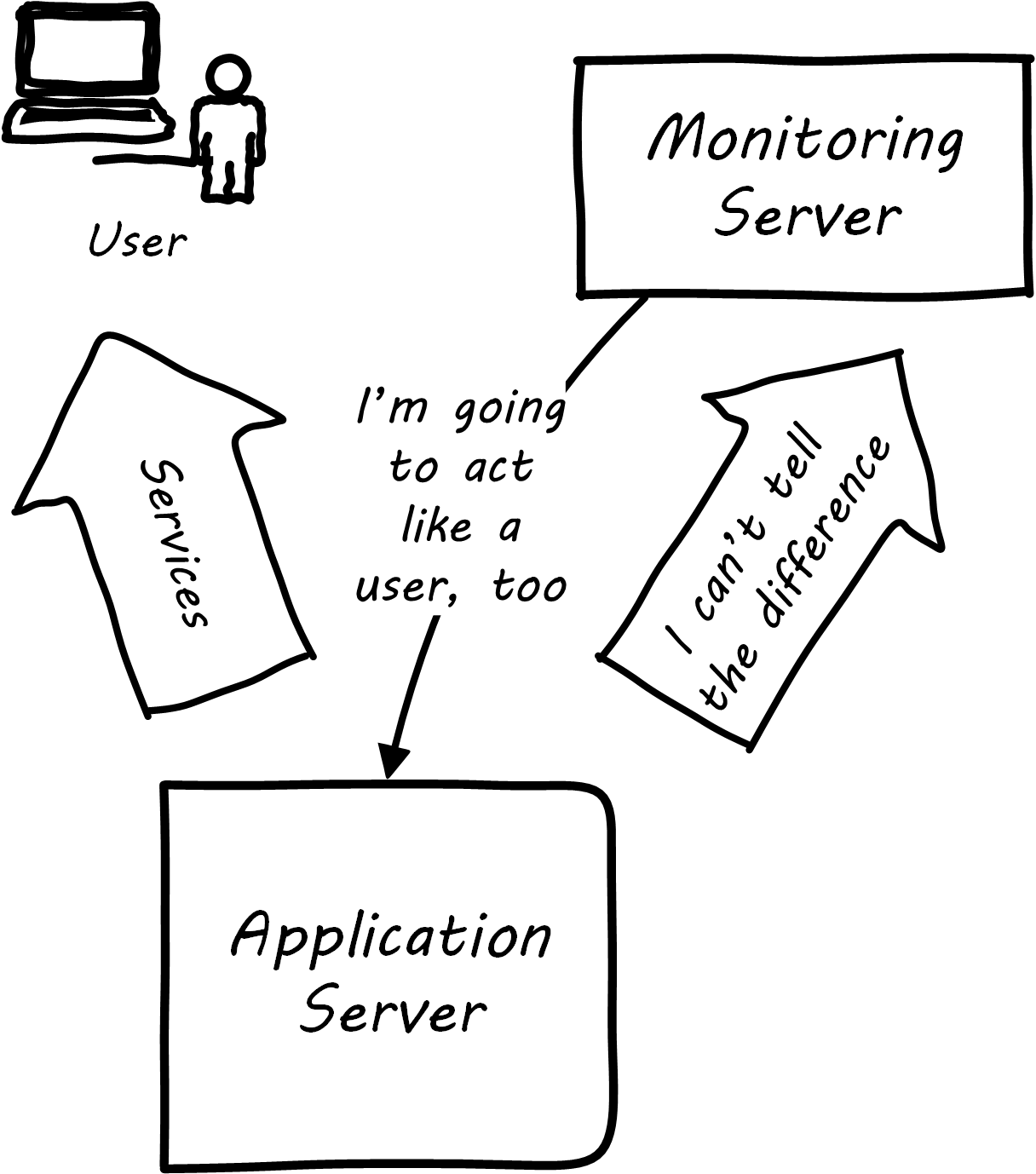
Some monitoring covers low-level system indicators not usually of direct interest to the end user. Other simulates end-user experience; SLAs are often defined in terms of the response time as experienced by the end user; see User Experience Monitoring. See Limoncelli et al. 2014, Chapters 16-17.
All of this data may then be forwarded to a central console and be integrated, with the objective of supporting the organization’s SLAs in priority order. Enterprise monitoring tools are notorious for requiring agents (small, continuously running programs) on servers; while some things can be detected without such agents, having software running on a given computer still provides the richest data. Since licensing is often agent-based, this gets expensive.
| Monitoring systems are similar to source control systems in that they are a critical point at which metadata diverges from the actual system under management. |
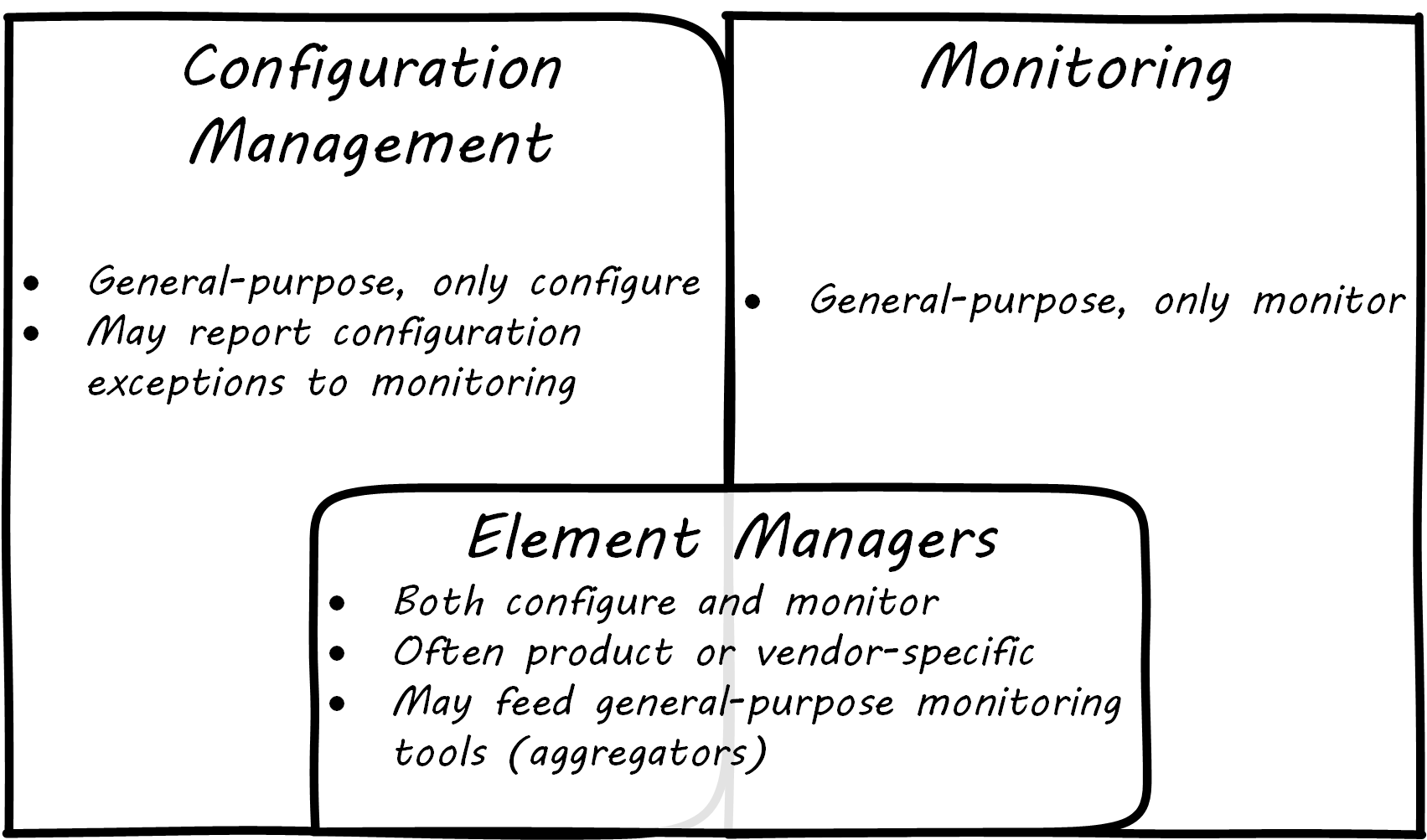
Related to monitoring tools is the concept of an element manager; see Configuration, Monitoring, and Element Managers. Element managers are low-level tools for managing various classes of digital or IT infrastructure. For example, Cisco® provides software for managing network infrastructure, and Dell EMC™ provides software for managing its storage arrays. Microsoft provides a variety of tools for managing various Windows components. Notice that such tools often play a dual role, in that they can both change the infrastructure configuration as well as report on its status. Many, however, are reliant on graphical user interfaces, which are falling out of favor as a basis for configuring infrastructure.
Specialized Monitoring
Monitoring tools, out of the box, can provide ongoing visibility to well-understood aspects of the digital product: the performance of infrastructure, the capacity utilized, and well-understood, common failure modes (such as a network link being down). However, the digital product or application also needs to provide its own specific telemetry in various ways; see Custom Software Requires Custom Monitoring. This can be done through logging to output files, or in some cases through raising alerts via the network.
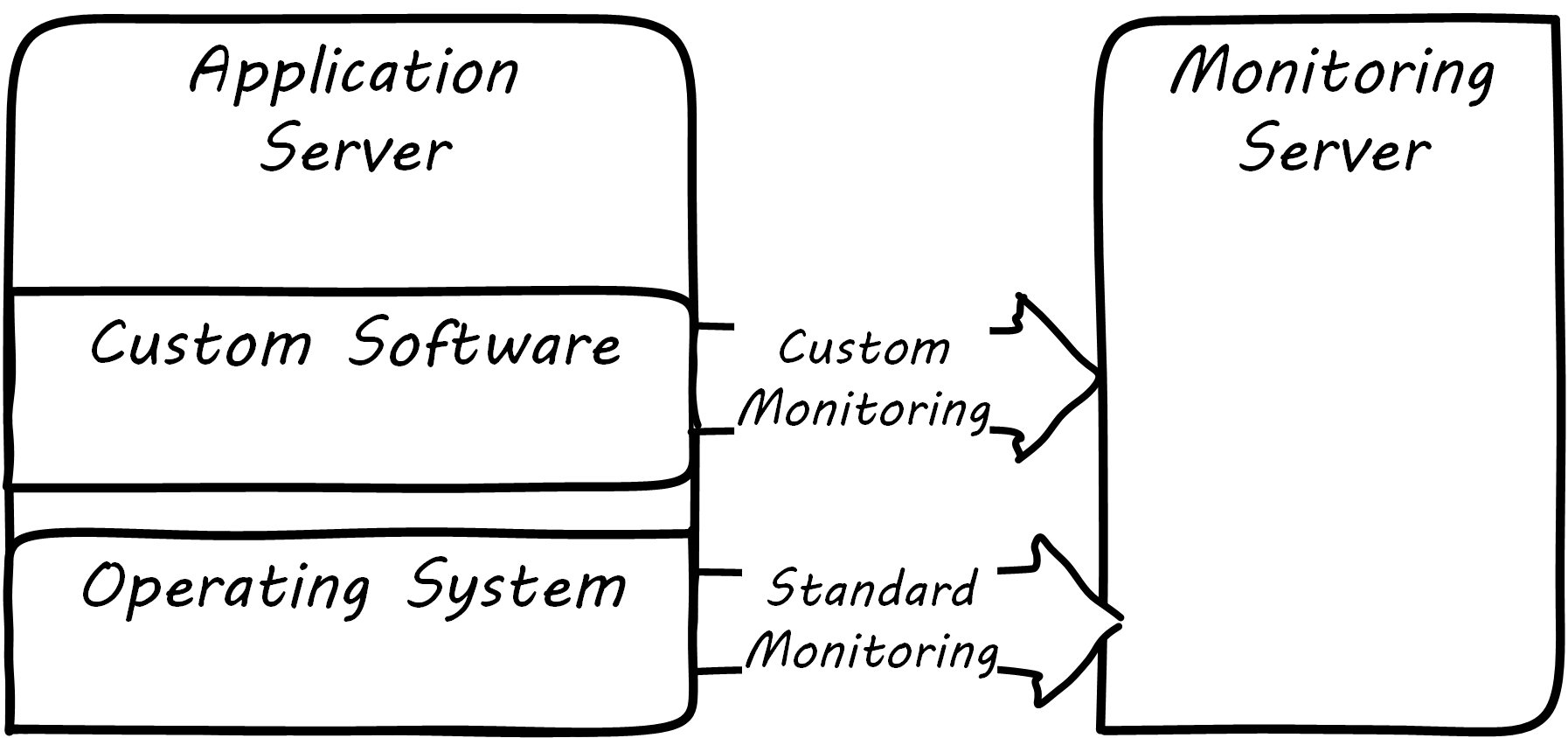
A typical way to enable custom monitoring is to first use a standard logging library as part of the software development process. The logging library provides a consistent interface for the developer to create informational and error messages. Often, multiple “levels” of logging are seen, some more verbose than others. If an application is being troublesome, a more verbose level of monitoring may be turned on. The monitoring tool is configured to scan the logs for certain information. For example, if the application writes:
APP-ERR-SEV1-946: Unresolvable database consistency issues detected, terminating application
into the log, the monitoring tool can be configured to recognize the severity of the message and immediately raise an alert.
Finally, as the quote at the beginning of this section suggests, it is critical that the monitoring discipline is based on continuous improvement. (There is more to come on continuous improvement in Coordination and Process.) Keeping monitoring techniques current with your operational challenges is a never-ending task. Approaches that worked well yesterday, today generate too many false positives, and your operations team is now overloaded with all the noise. Ongoing questioning and improvement of your approaches are essential to keeping your monitoring system optimized for managing business impact as efficiently and effectively as possible.
Aggregation and Operations Centers
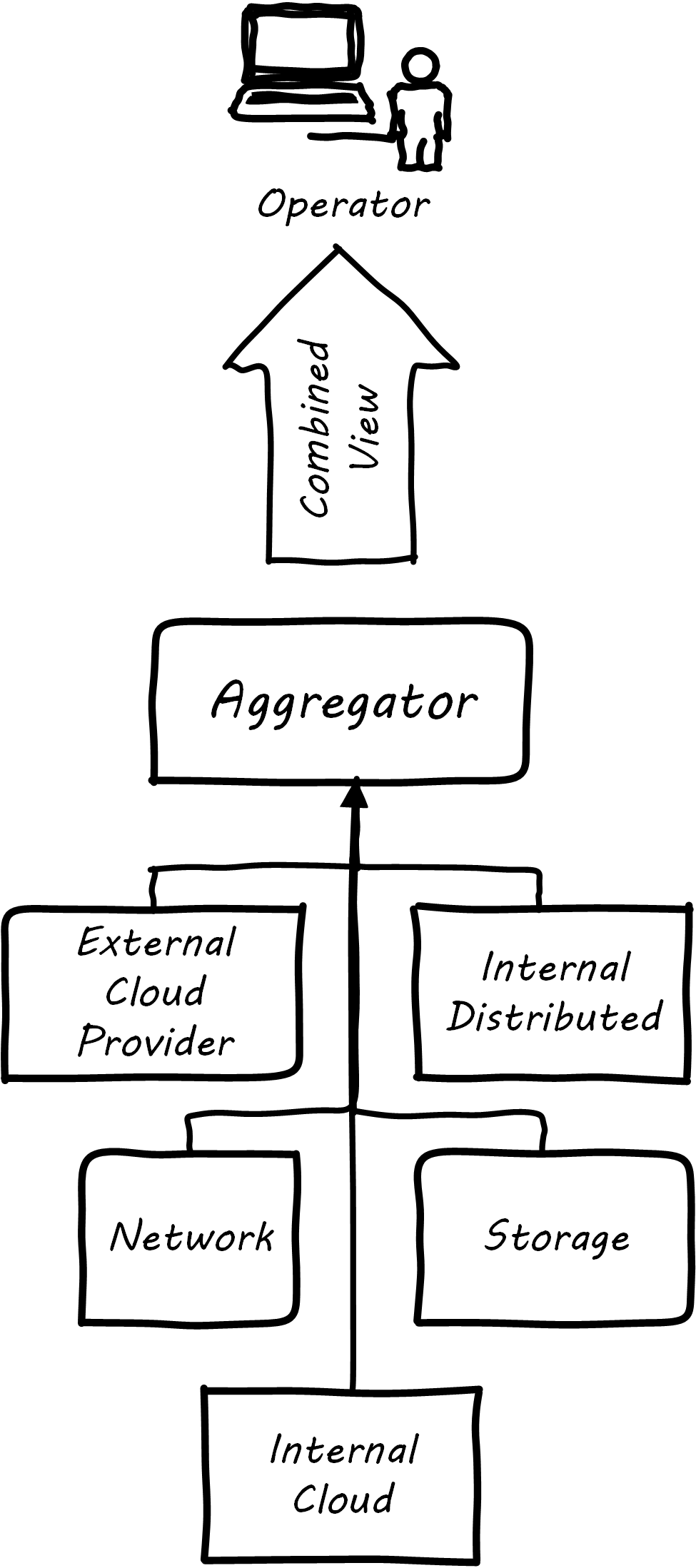
It is not possible for a 24x7 operations team to access and understand the myriads of element managers and specialized monitoring tools present in the large IT environment. Instead, these teams rely on aggregators of various kinds to provide an integrated view of the complexity; see Aggregated Monitoring. These aggregators may focus on status events, or specifically on performance aspects related either to the elements or to logical transactions flowing across them. They may incorporate dependencies from configuration management to provide a true “business view” into the event streams. This is directly analogous to the concept of Andon board from Lean practices or the idea of “information radiator” from Agile principles.
| “24x7” operations means operations conducted 24 hours a day, 7 days a week. |
A monitoring console may present a rich and detailed set of information to an operator. Too detailed, in fact, as systems become large. Raw event streams must be filtered for specific events or patterns of concern. Event de-duplication starts to become an essential capability, which leads to distinguishing the monitoring system from the event management system. Also, for this reason, monitoring tools are often linked directly to ticketing systems; on certain conditions, a ticket (e.g., an incident) is created and assigned to a team or individual.
Enabling a monitoring console to auto-create tickets, however, needs to be carefully considered and designed. A notorious scenario is the “ticket storm”, where a monitoring system creates multiple (perhaps thousands) of tickets, all essentially in response to the same condition.
Understanding Business Impact
At the intersection of event aggregation and operations centers is the need to understand business impact. It is not, for example, always obvious what a server is being used for. This may be surprising to those who are new, and perhaps also to those with experience in smaller organizations. However, in many large “traditional” IT environments, where the operations team is distant from the development organization, it is not necessarily easy to determine what a given hardware or software resource is doing or why it is there. Clearly, this is unacceptable in terms of security, value management, and any number of other concerns. However, from the start of distributed computing, the question “what is on that server?” has been all too frequent in large IT shops.
In mature organizations, this may be documented in a Configuration Management Database or System (CMDB/CMS). Such a system might start by simply listing the servers and their applications, as Applications and Servers shows.
| Application | Server |
|---|---|
Quadrex® |
SRV0001 |
PL-Q |
SRV0002 |
Quadrex |
DBSRV001 |
Time Trek™ |
SRV0003 |
HR-Portal |
SRV0003 |
etc. |
etc. |
Imagine the above list, 25,000 rows long.
This is a start, but still does not tell us enough. A more elaborate mapping might include business unit and contact; see Business Units, Contacts, Applications, Servers.
| BU | Contact | Application | Server |
|---|---|---|---|
Logistics |
Mary Smith |
Quadrex |
SRV0001 |
Finance |
Aparna Chaudry |
PL-Q |
SRV0002 |
Logistics |
Mary Smith |
Quadrex |
DBSRV001 |
Human Resources |
William Jones |
TimeTrak |
SRV0003 |
Human Resources |
William Jones |
HR-Portal |
SRV0003 |
etc. |
etc. |
etc. |
etc. |
The above lists are very simple examples of what can be extensive record-keeping. But the key user story is implied: if we cannot ping SRV0001, we know that the Quadrex application supporting Logistics is at risk, and we should contact Mary Smith as soon as possible, if she has not already contacted us. (Sometimes, the user community calls right away; in other cases, they may not, and proactively contacting them is a positive and important step.)
The above approach is relevant to older models still reliant on servers (whether physical or virtual) as primary units of processing. The trend to more dynamic forms of computing such as containers and serverless computing is challenging these traditional practices, and what will replace them is currently unclear.
Capacity and Performance Management
Capacity and performance management are closely related, but not identical terms encountered as IT systems scale up and encounter significant load.
A capacity management system may include large quantities of data harvested from monitoring and event management systems, stored for long periods of time so that history of the system utilization is understood and some degree of prediction can be ventured for upcoming utilization.
The classic example of significant capacity utilization is the Black Friday/Cyber Monday experience of retailers. Both physical store and online e-commerce systems are placed under great strain annually around this time, with the year’s profits potentially on the line.
Performance management focuses on the responsiveness (e.g., speed) of the systems being used. Responsiveness may be related to capacity utilization, but some capacity issues do not immediately affect responsiveness. For example, a disk drive may be approaching full. When it fills, the system will immediately crash, and performance is severely affected. But until then, the system performs fine. The disk needs to be replaced on the basis of capacity reporting, not performance trending. On the other hand, some performance issues are not related to capacity. A misconfigured router might badly affect a website’s performance, but the configuration simply needs to be fixed – there is no need to handle as a capacity-related issue.
At a simpler level, capacity and performance management may consist of monitoring CPU, memory, and storage utilization across a given set of nodes, and raising alerts if certain thresholds are approached. For example, if a critical server is frequently approaching 50% CPU utilization (leaving 50% “headroom”), engineers might identify that another server should be added. Abbott and Fisher suggest: “As a general rule … we like to start at 50% as the ideal usage percentage and work up from there as the arguments dictate” [Abbott & Fisher 2015].
So, what do we do when a capacity alert is raised, either through an automated system or through the manual efforts of a capacity analyst? There are a number of responses that may follow:
-
Acquire more capacity
-
Seek to use existing capacity more efficiently
-
Throttle demand somehow
Capacity analytics at its most advanced (i.e., across hundreds or thousands of servers and services) is a true Big Data problem domain and starts to overlap with IT asset management, capital planning, and budgeting in significant ways. As your organization scales up and you find yourself responding more frequently to the kinds of operational issues described in this section, you might start asking yourself whether you can be more proactive. What steps can you take when developing or enhancing your systems, so that operational issues are minimized? You want systems that are stable, easily upgraded, and that can scale quickly on-demand.
Evidence of Notability
Monitoring production systems is the subject of extensive discussion and literature in digital and IT management; see, for example, Allspaw & Robbins 2010, Limoncelli et al. 2014, and Beyer et al. 2016.
Limitations
Monitoring provides immediate insight via the automated management of telemetry. It cannot tell responders what to do, in general.
Related Topics