Digital Governance
Description
The legacy of IT governance is wide, deep, and often wasteful. Approaches based on misapplied Taylorism and misguided, CMM-inspired statistical process control have resulted in the creation of ineffective, large-scale IT bureaucracies whose sole mission seems to be the creation and exchange of non-value-add secondary artifacts, while lacking any clear concept of an execution model.
What is to be done? Governance will not disappear any time soon. Simply arguing against governance is unlikely to succeed. Instead, this document argues the most effective answer lies in a re-examination of the true concerns of governance:
-
Sustaining innovation and effective value delivery
-
Maintaining efficiency
-
Optimizing risk
These fundamental principles (“top-line”, “bottom-line”, “risk”) define value for organizations around the world, whether for-profit, non-profit, or governmental. After considering the failings of IT governance, we will re-examine it in light of these objectives and come up with some new answers for the digital era.
From the perspective of Digital Transformation, there are many issues with traditional IT governance and the assumptions and practices characterizing it.
The New Digital Operating Model
Consider the idea of “programmability” mentioned at the start of this Competency Category. A highly “programmable” position is one where responsibilities can be specified in terms of their activities. And what is the fundamental reality of Digital Transformation? It is no accident that such positions are called “programmable”. In fact, they are being “programmed away” or “eaten by software” – leaving only higher-skill positions that are best managed by objectives, and which are more sensitive to cultural dynamics.
Preoccupation with “efficiency” fades as a result of the decreasingly “programmable” component of work. The term “efficiency” signals a process that has been well-defined (is “programmable”) to the point where it is repeatable and scalable. Such processes are ripe for automation, commoditization, and outsourcing, and this is in fact happening.
If the repetitive process is retained within an organization, the drive for efficiency leads to automation and, eventually, efficiency is expressed through concerns for capacity management and the consumption of computing resources. And when such repetitive concerns are not retained by the organization, but instead become a matter of sourcing rather than execution, the emphasis shifts to risk management and governance of the supplier.
The remaining uncertain and creative processes should not just be managed for “efficiency” and need to be managed for effectiveness, including fast feedback, collaboration, culture, and so forth.
Project versus Operations as Operating Model
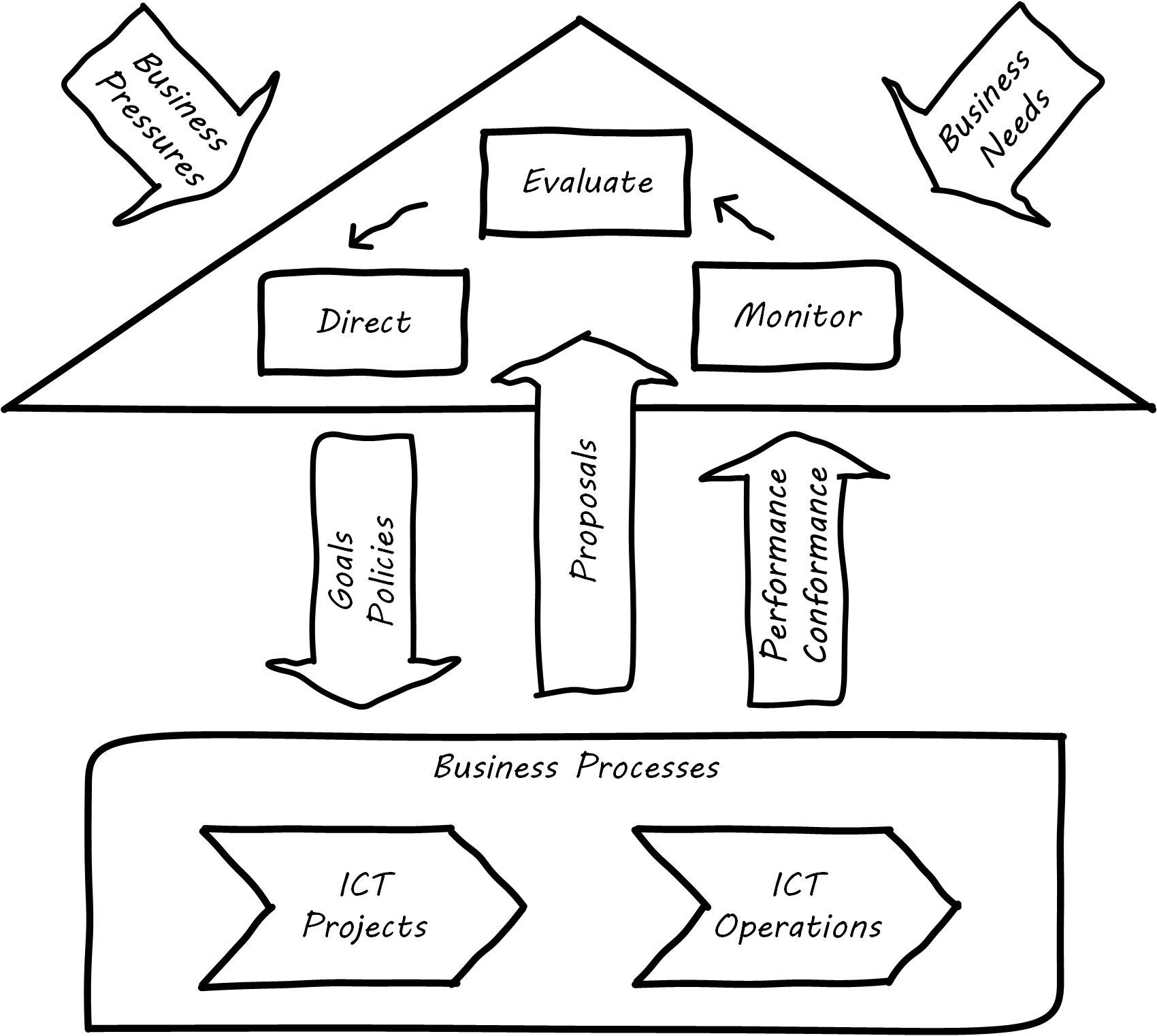
As we can see in Governance Based on Project versus Operations (similar to ISO/IEC 38500:2008), ISO/IEC 38500:2008 assumes a specific IT operating model, one in which projects are distinct from operations. We have discussed the growing influence of product-centric digital management throughout this document, but as of the time of writing the major IT governance standard still does not recognize it. The ripple effects are seen throughout other guidance and commentary. In particular, the project-centric mindset is closely aligned with the idea of IT and the CIO as primarily order-takers.
CIO as Order-Taker
Throughout much of the IT governance guidance, certain assumptions become evident:
-
There is an entity that can be called “the Business”
-
There is a distinct entity called “IT” (for “Information Technology”)
-
It is the job of “IT” to take direction, i.e., orders, from “the Business” and to fulfill them
-
There is a significant risk that “IT” activities (and by extension, money spent on them) may not be correctly allocated to the preferred priorities of “the Business”; IT may spend money unwisely, on technology for its own sake, and this risk needs to be controlled
-
The needs of “the Business” can be precisely defined and it is possible for “IT” to support those needs with a high degree of predictability as to time and cost; this predictability is assumed even when those activities imply multi-million dollar investments and months or years of complex implementation activities
-
When such activities do not proceed according to initial assumptions, this is labeled an “IT failure”; it is assumed that the failure could have been prevented through more competent management, “rigorous” process, or diligent governance, especially on the IT side
There may be organizations where these are reasonable assumptions. (This document does not claim they do not exist.) But there is substantial evidence for the existence of organizations for whom these assumptions are untrue.
The Fallacies of “Rigor” and Repeatability
One of the most critical yet poorly understood facts of software development and by extension complex digital system innovation is the impossibility of “rigor”. Software engineers are taught early that “completely” testing software is impossible [Kaner 1999], yet it seems that this simple fact (grounded in fundamentals of computer science and information theory) is not understood by many managers.
A corollary fallacy is that of repeatable processes, when complexity is involved. We may be able to understand repeatability at a higher level, through approaches like case management or the Checklist Manifesto's submittal schedules, but process control in the formal sense within complex, R&D-centric digital systems delivery is simply impossible, and the quest for it is essentially cargo cult management.
And yet, IT governance discussions often call for “repeatability” (e.g., Moeller 2013), despite the fact that value that can be delivered “repeatably”, year after year, is, for the most part, commodity production, and not innovative product development. Strategy is notably difficult to commoditize.
Another way to view this is in terms of the decline of traditional IT. As you review those diagrams, understand that much of IT governance has emerged from the arguably futile effort to deliver product innovation in a low-risk, “efficient” manner. This desire has led, as Ambler and Lines note at the top of this Competency Category, to the creation of layers and layers of bureaucracy and secondary artifacts.
The cynical term for this is “theater”, as in an act that is essentially unreal but presented for the entertainment and distraction of an audience.
As we noted above, a central reality of Digital Transformation is that commoditized, predictable, programmable, repeatable, “efficient” activities are being quickly automated, leaving governance to focus more on the effectiveness of innovation (e.g., product development) and management of supplier risk. Elaborate IT operating models specifying hundreds of interactions and deliverables, in a futile quest for “rigor” and “predictability”, are increasingly relics of another time.
Digital Effectiveness
Let us return to the first value objective: effectiveness. We define effectiveness as “top-line” benefits: new revenues and preserved revenues. New revenues may come from product innovation, as well as successful marketing and sales of existing products to new markets (which itself is a form of innovation).
Traditionally, “back-office” IT was rarely seen as something contributing to effectiveness, innovation, and top-line revenue. Instead, the first computers were used to increase efficiency, through automating clerical work. The same processes and objectives could be executed for less money, but they were still the same back-office processes.
With Digital Transformation, product innovation and effectiveness is now a much more important driver. Yet product-centric management is still poorly addressed by traditional IT governance, with its emphasis on distinguishing projects from operations.
One tool that becomes increasingly important is a portfolio view. While PMOs may use a concept of “portfolio” to describe temporary initiatives, such project portfolios rarely extend to tracking ongoing operational benefits. Alternative approaches also should be considered such as the idea of an options approach.
Digital Efficiency
Efficiency is a specific, technical term, and although often inappropriately prioritized, is always an important concern. Even a digitally transforming, product-centric organization can still have governance objectives of optimizing efficiency. Here are some thoughts on how to re-interpret the concept of efficiency.
Consolidate the Pipelines
One way in which digital organizations can become more efficient is to consolidate development as much as possible into common pipelines. Traditionally, application teams have owned their own development and deployment pipelines, at the cost of great, non-value add variability. Even centralizing source control has been difficult.
This is challenging for organizations with large legacy environments, but full lifecycle pipeline automation is becoming well understood across various environments (including the mainframe).
Reduce Internal Service Friction
Another way of increasing efficiency is to standardize integration protocols across internal services, as Amazon has done. This reduces the need for detailed analysis of system interaction approaches every time two systems need to exchange data. This is a form of reducing transaction costs and, therefore, is consistent with Coase’s The Nature of the Firm [Coase 1937].
Within the boundary of a firm, a collaboration between internal services should be easier because of reduced transaction costs. It is not hard to see that this would be the case for digital organizations: security, accounting, and CRM would all be more challenging and expensive for externally-facing services.
However, since a firm is a system, a service within the boundaries of a firm will have more constraints than a service constrained only by the market. The internal service may be essential to other, larger-scoped services, and may derive its identity primarily from that context.
Because the need for the service is well understood, the engineering risk associated with the service may also be reduced. It may be more of a component than a product. See the parable of the the Flower and the Cog. Reducing service redundancy is a key efficiency goal within the bounds of a system – more to come on this in Architecture and Portfolio.
Manage the Process Portfolio
Processes require ongoing scrutiny. The term “organizational scar tissue” is used when specific situations result in new processes and policies, that in turn increase transactional friction and reduce efficiency throughout the organization.
Processes can be consolidated, especially if specific procedural detail can be removed in favor of larger-grained Case Management or Checklist Manifesto concepts including the submittal schedule. As part of eventual automation and Digital Transformation, processes can be ranked as to how “heavyweight” they are. A typical hierarchy, from “heaviest” to “lightest”, might be:
-
Project
-
Release
-
Change
-
Service request
-
Automated self-service
The organization might ask itself:
-
Do we need to manage this as a project; why not just a release?
-
Do we need to manage this as a release; why not just a change?
-
Do we need to manage this as a change; why not just a service request?
-
Do we need to manage this as a service request; why is it not fully automated self-service?
There may be a good reason to retain some formality. The point is to keep asking the question. Do we really need a separate process? Or can the objectives be achieved as part of an existing process or another element?
Treat Governance as Demand
A steam engine’s governor imposes some load, some resistance, on the engine. In the same way, governance activities and objectives, unless fully executed by the directing body (e.g., the Board), themselves impose a demand on the organization.
This points to the importance of having a clear demand/execution framework in place to manage governance demand. The organization does not have an unlimited capacity for audit response, reporting, and the like. In order to understand the organization as a system, governance demand needs to be tracked and accounted for and challenged for efficiency just as any other sort of demand.
Leverage the Digital Pipeline
Finally, efficiency asks: can we leverage the digital pipeline itself to achieve governance objectives? This is not a new idea. The governance/management interface must be realized by specific governance elements, such as processes. Processes can (and often should) be automated. Automation is the raison d’etre of the digital pipeline; if the process can be expressed as user stories, behavior-driven design, or other forms of requirement, it simply is one more state change moving from dev to ops.
In some cases, the governance stories must be applied to the pipeline itself. This is perhaps more challenging, but there is no reason the pipeline itself cannot be represented as code and managed using the same techniques. The automated elements then can report their status up to the monitoring activity of governance, closing the loop. Auditors should periodically re-assess their effectiveness.
Digital Risk Management
Finally, from an IT governance perspective, what is the role of IT risk management in the new digital world? It is not that risk management goes away. Many risks that are well understood today will remain risks for the foreseeable future. But there are significant new classes of risk that need to be better understood and managed:
-
Unmanaged demand and disorganized execution models leading to multi-tasking, which is destructive of value and results
-
High queue wait states, resulting in uncompetitive speed to deliver value
-
Slow feedback due to large batch sizes, reducing effectiveness of product discovery
-
New forms of supplier risk, as services become complex composites spanning the Internet ecosystem
-
Toxic cultural dynamics destructive of high team performance
-
Failure to incorporate cost of delay in resource allocation and work prioritization decisions
All of these conditions can reduce or destroy revenues, erode organizational effectiveness, and worse. It is hard to see them as other than risks, yet there is little attention to such factors in the current “best practice” guidance on risk.
Cost of Delay as Risk
In today’s digital governance there must be a greater concern for outcome and effectiveness, especially in terms of time-to-market (minimizing cost of delay). Previously, concerns for efficiency might lead a company to overburden its staff, resulting in queuing gridlock, too much work-in-process, destructive multi-tasking, and ultimately failure to deliver timely results (or deliver at all).
Such failure to deliver was tolerated because it seemed to be a common problem across most IT departments. Also relevant is the fact that Digital Transformation had not taken hold yet. IT systems were often back-office, and delays in delivering them (or significant issues in their operation) were not quite as damaging.
Now, the effectiveness of delivery is essential. The interesting, and to some degree unexpected result, is that both efficiency and risk seem to be benefiting as well. Cross-functional, focused teams are both more effective and more efficient, and able to manage risk better as well. Systems are being built with both increased rapidity as well as improved stability, and the automation enabling this provides robust audit support.
Team Dynamics as Risk
We have covered culture in some depth in Coordination and Process. Briefly, from a governance perspective, the importance of organizational culture has been discussed by management thinkers since at least W. Edwards Deming. In a quote often attributed to Peter Drucker: “culture eats strategy for breakfast”. But it has been difficult at best to quantify what we mean by culture.
Quantify? Some might even say quantification is impossible. But Google and the State of DevOps research have done so. Google has established the importance of psychological safety in forming effective, high-performing teams [Rozovsky 2015]. And the State of DevOps research, applying the Westrum typology, has similarly confirmed that pathological, controlling cultures are destructive of digital value [Puppet Labs 2015].
These facts should be taken seriously in digital governance discussions. So-called “toxic” leadership (an increasing concern in the military itself [Vergun 2015]) is destructive of organizational goals and stakeholder value. It can be measured and managed and should be a matter of attention at the highest levels of organizational governance.
Sourcing Risk
We have already covered contracting in terms of software and cloud. But in terms of the emergence model, it is typical that companies enter into contracts before having a fully mature sourcing and contract management capability with input from the GRC perspective.
We have touched on the issues of cloud due diligence and sourcing and security in this Competency Area. The 2e2 case discussed [Venkatraman 2013] is interesting; it seems that due diligence had actually been performed. Additional controls could have made a key difference, in particular business continuity planning.
There are a wide variety of supplier-side risks that must be managed in cloud contracts:
-
Access
-
Compliance
-
Data location
-
Multi-tenancy
-
Recovery
-
Investigation
-
Viability (assurance)
-
Escrow
We have emphasized throughout this document the dynamic nature of digital services. This presents a challenge for risk management of digital suppliers. This year’s audit is only a point-in-time snapshot; how to maintain assurance with a fast-evolving supplier? This leading edge of cloud sourcing is represented in discussions such as Dynamic Certification of Cloud Services: Trust, But Verify: “The on-demand, automated, location-independent, elastic, and multi-tenant nature of cloud computing systems is in contradiction with the static, manual, and human process-oriented evaluation and certification process designed for traditional IT systems … Common certificates are a backward look at the fulfillment of technical and organizational measures at the time of issue and therefore represent a snapshot. This creates a gap between the common certification of one to three years and the high dynamics of the market for cloud services and providers. The proposed dynamic certification approach adopts the common certification process to the increased flexibility and dynamics of cloud computing environments through using automation potential of security controls and continuous proof of the certification status” [Lins et al. 2016].
It seems likely that such ongoing dynamic evaluation of cloud suppliers would require something akin to Simian Army techniques, discussed below.
Beyond increasing supply-side dynamism, risk management in a full SIAM sense is compounded by the complex interdependencies of the services involved. All of the cloud contracting risks need to be covered, as well as further questions such as:
-
If a given service depends on two sub-services (“underpinning contracts”), what are the risks for the failure of either or both of the underpinning services?
-
What are the controls?
Automating Digital Governance
Digital Exhaust
One governance principle we will suggest here is to develop a governance architecture as an inherent part of the delivery system, not as an additional set of activities. We use the concept of “digital exhaust” to reinforce this.
Digital exhaust, for the purposes of this document, consists of the extraneous data, and information that can be gleaned from it, originating from the development and delivery of IT services.
Consider an automobile’s exhaust. It does not help you get to where you are going, but it is an inevitable aspect of having an internal combustion engine. Since you have it, you can monitor it and gain certain insights as to whether your engine is running efficiently and effectively. You might even be able to identify if you are at risk of an engine failure.
The term “digital exhaust” is also applied to the data generated from the IoT. This usage is conceptually aligned to our usage here, but somewhat different in emphasis.
To leverage digital exhaust, focus on the critical, always-present systems that enable digital delivery:
-
In Digital Infrastructure we introduced the concept of version control
-
In Application Delivery we introduced the idea of a continuous delivery pipeline
-
In Digital Operations we introduced monitoring as part of operations
These systems constitute a core digital pipeline, one that can be viewed as an engine producing digital exhaust. This is in contrast to fragmented, poorly automated pipelines, or organizations with little concept of pipeline at all. Such organizations end up relying on secondary artifacts and manual processes to deliver digital value.
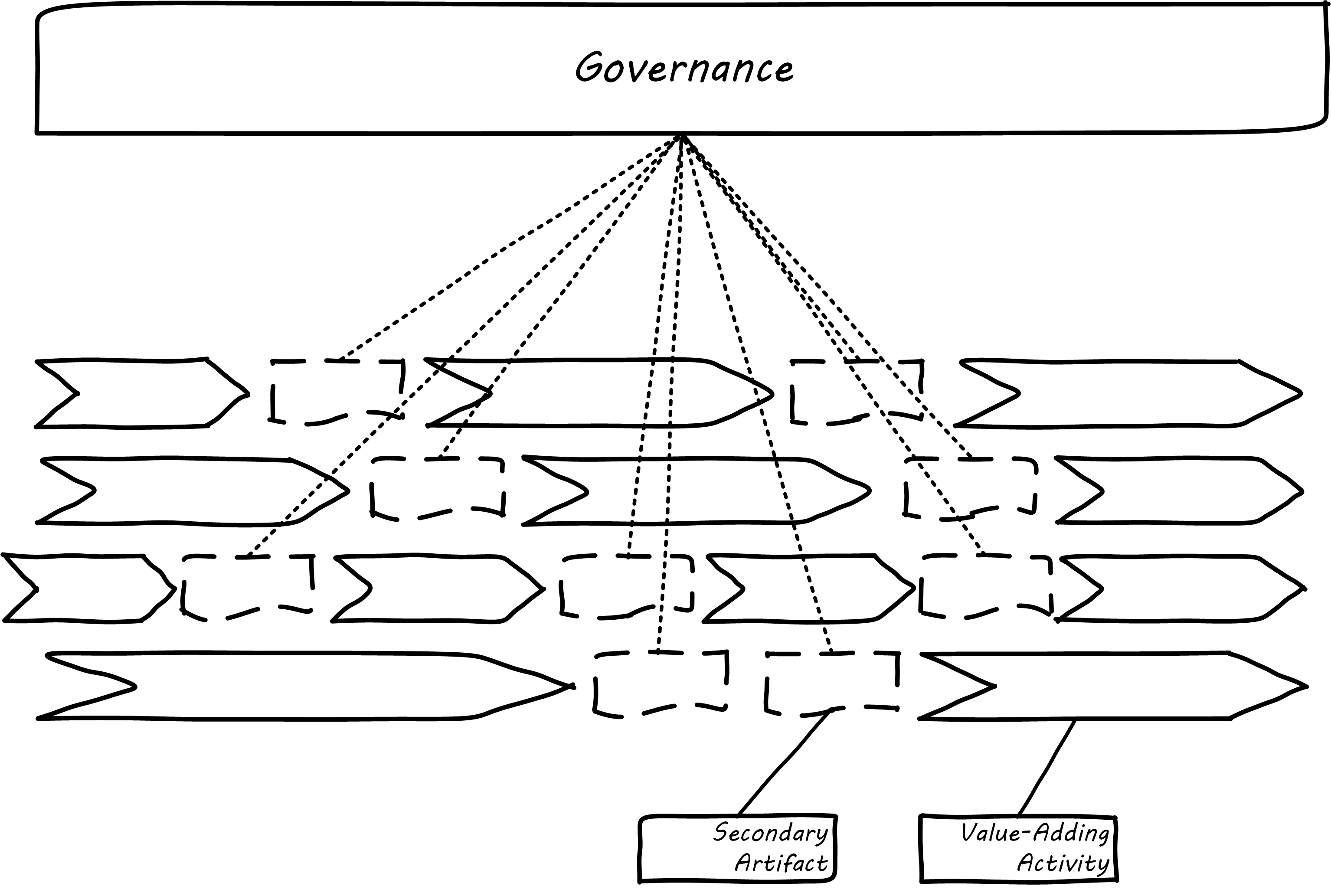
The illustration in Governance Based on Activities and Artifacts represents fragmented delivery pipelines, with many manual processes, activities, and secondary artifacts (waterfall stage approvals, designs, plans, manual ticketing, and so forth). Much IT governance assumes this model, and also assumes that governance must often rely on aggregating and monitoring the secondary artifacts.
In contrast, with a rationalized continuous delivery pipeline, governance increasingly can focus on monitoring the digital exhaust; see Governance of Digital Exhaust.
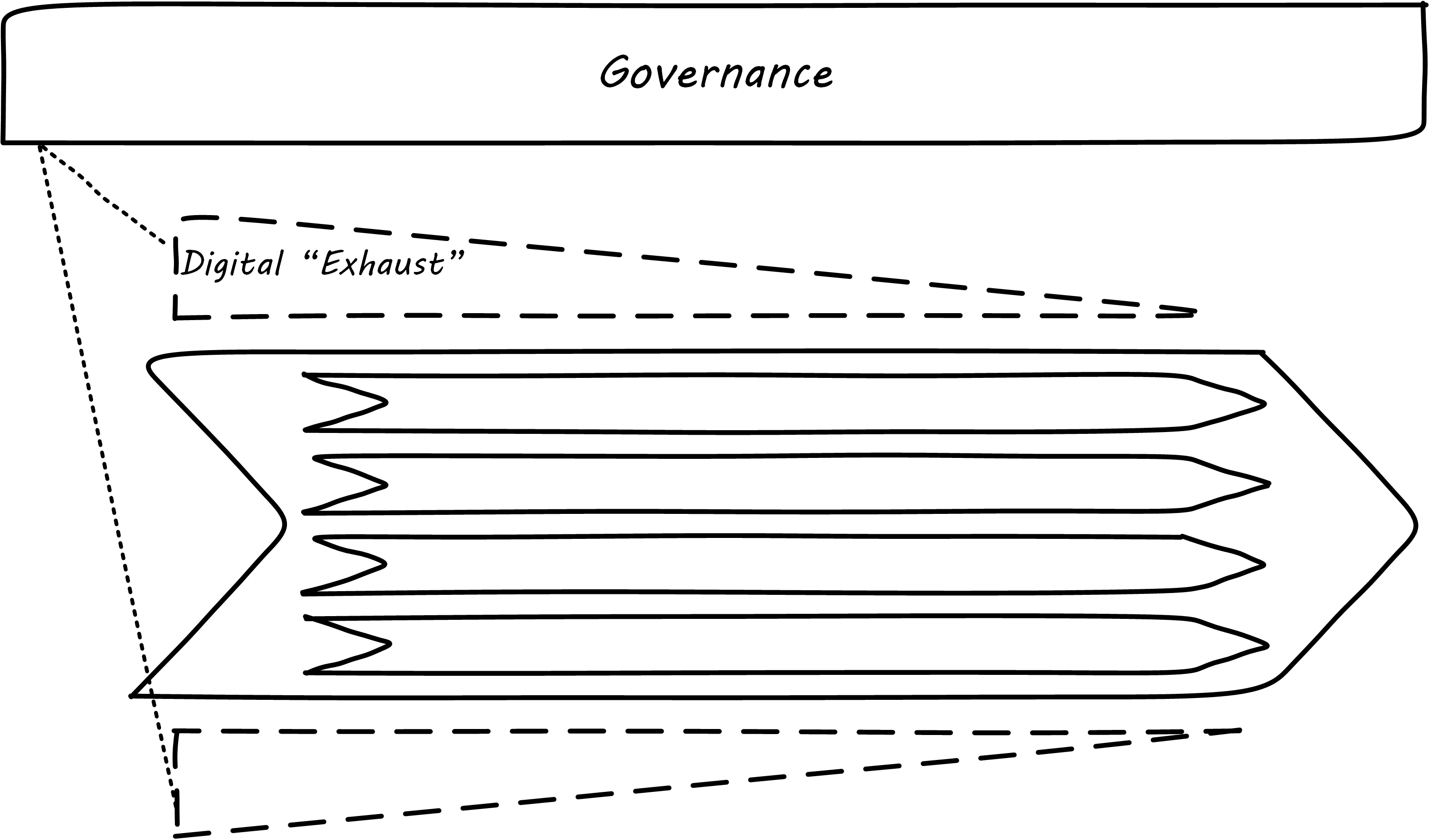
What can we monitor with digital exhaust for the purposes of governance?
-
Development team progress against backlog
-
Configuration management
-
Conformance to architectural standards (through inspection of source and package managers, code static analysis, and other techniques)
-
Complexity and technical debt
-
Performance and resource consumption of services
-
Performance of standards against automated hardening activities (e.g., Simian Army)
As noted above, certain governance objectives may require the pipeline itself to be adapted; e.g., the addition of static code analysis, or the implementation of hardening tools such as Simian Army.
Additional Automation
The DevOps Audit Toolkit provides an audit perspective on pipeline automation [DeLuccia et al. 2015]. This report provides an important set of examples demonstrating how modern DevOps toolchain automation can fulfill audit objectives as well or better than “traditional” approaches. This includes a discussion of alternate approaches to the traditional control of “separation of duties” for building and deploying code. These approaches include automated code analysis and peer review as a required control.
There are a variety of ways the IT pipeline can be automated. Many components are seen in real-world pipelines, including:
-
Source repositories
-
Build managers
-
Static code analyzers
-
Automated user interface testing
-
Load testing
-
Package managers
-
More sophisticated continuous deployment infrastructure
Additionally, there may still be a need for systems that are secondary to the core pipeline:
-
Service or product portfolio
-
Workflow and Kanban-based systems (one notable example is workflow to ensure peer review of code)
-
Document management
There may also be a risk repository if the case cannot be made to track risks using some other system. The important thing to remember when automating risk management is that risks are always with respect to some thing.
A risk repository needs to be integrated with subject inventories, such as the Service Portfolio and relevant source repositories and entries in the package manager. Otherwise, risk management will remain an inefficient, highly manual process.
What are the things that may present risks?
-
Products/services
-
Their ongoing delivery
-
Their changes and transformations (releases)
-
Their revenues
-
-
Customers and their data
-
Employees and their positions
-
Assets
-
Vendors
-
Other critical information
Evidence of Notability
There is substantial friction between classical governance concerns and new digital operating models; see Jez Humble’s Lean Enterprise: Adopting Continuous Delivery, DevOps, and Lean Startup at Scale [Humble et al. 2014] for one discussion. The DevOps Audit Defense Toolkit [DeLuccia et al. 2015] provides another window into this topic.
Limitations
The Lean and Agile challenge to governance arises primarily in R&D-centric environments. Classic governance practices are well suited for purely operational environments, where they have been honed over decades.
Related Topics