Defining Operations Management
Defining Operations
Description
Operations management is a broad topic in management theory, with whole programs dedicated to it in both business and engineering schools. Companies frequently hire a Chief Operating Officer (COO) to run the organization. We started to cover operations management in Work Management where we examined the topic of “work management” – in traditional operations management, the question of work and who is doing it is critical. For the Digital Practitioner, “operations” tends to have a more technical meaning than the classic business definition, being focused on the immediate questions of systems integrity, availability and performance, and feedback from the user community (i.e., the service or help desk). We see such a definition from Limoncelli et al.: “… operations is the work done to keep a system running in a way that meets or exceeds operating parameters specified by a Service-Level Agreement (SLA). Operations includes all aspects of a service’s lifecycle: from initial launch to the final decommissioning and everything in between” [Limoncelli et al. 2014].
Operations often can mean “everything but development” in a digital context. In the classic model, developers built systems and “threw them over the wall” to operations. Each side had specialized processes and technology supporting their particular concerns. However, recall our discussion of design thinking – the entire experience is part of the product. This applies to both those consuming it as well as running it. Companies undergoing Digital Transformation are experimenting with many different models, as we will see in Context III, up to and including the complete merging of development and operations-oriented skills under common product management.
| In a digitally transformed enterprise, operations is part of the product. |
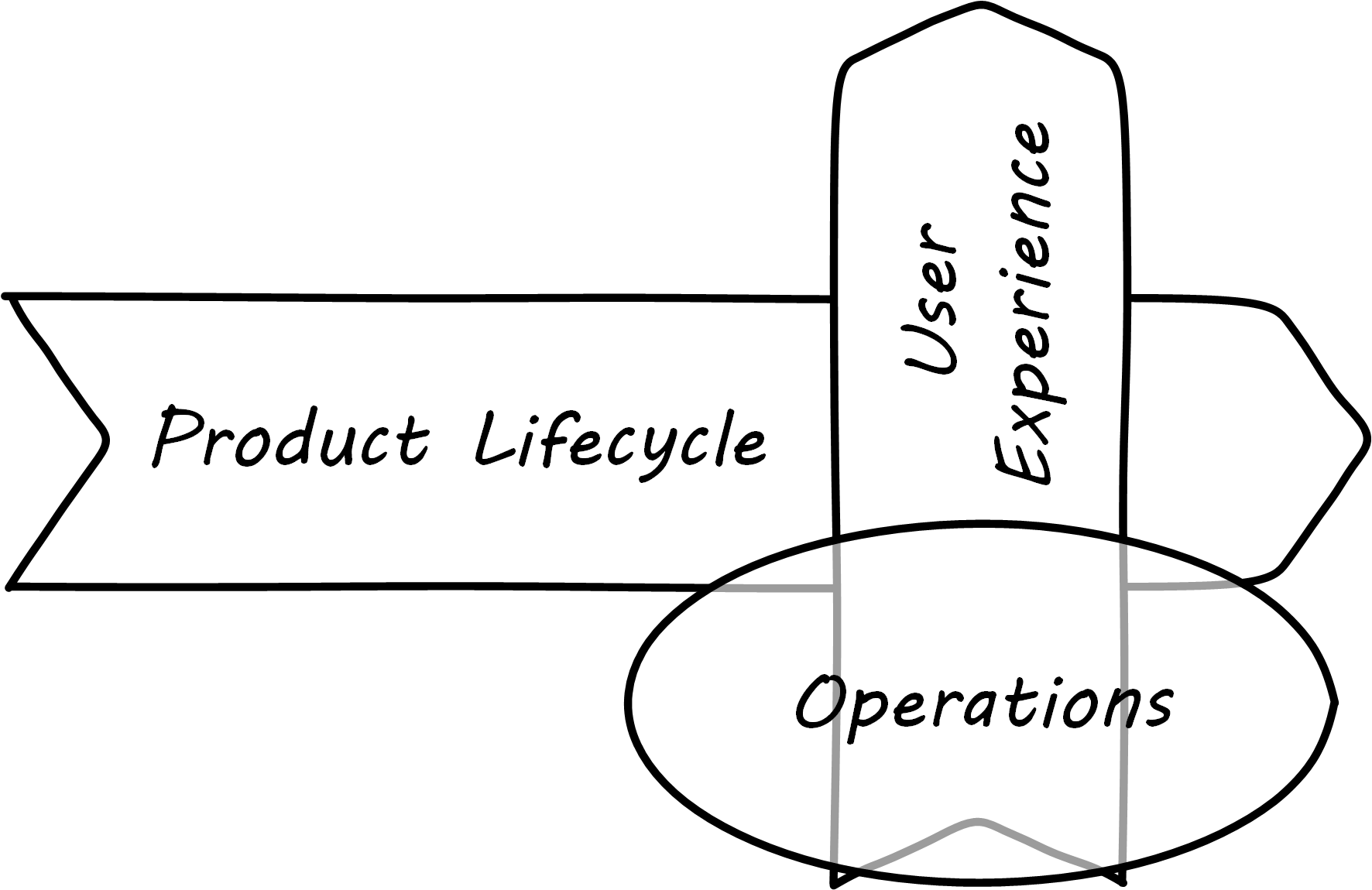
Since this document has a somewhat broader point of view covering all of digital management, it uses the following definition of operations:
Operations is the direct facilitation and support of the digital value experience. It tends to be less variable, more repeatable, yet more interrupt-driven than product development work. It is more about restoring a system to a known state, and less about creating new functionality.
What do we mean by this? In terms of our dual-axis value chain, operations supports the day-to-day delivery of the digital “moment of truth”; see Operations Supports the Digital Moment of Truth.
The following are examples of “operations” in an IT context. Some are relevant to a “two pizza product team” scenario and some might be more applicable to larger environments:
-
Systems operators are sitting in 24x7 operations centers, monitoring system status and responding to alerts
-
Help desk representatives answering phone calls from users requiring support
-
They may be calling because a system or service they need is malfunctioning
They may also be calling because they do not understand how to use the system for the value experience they have been led to expect from it. Again, this is part of their product experience.
-
-
Developers and engineers serving “on call” on a rotating basis to respond to systems outages referred to them by the operations center
-
Data center staff performing routine work, such as installing hardware, granting access, or running or testing backups; such routine work may be scheduled, or it may be on request (e.g., ticketed)
-
Field technicians physically dispatched to a campus or remote site to evaluate and if necessary update or fix IT hardware and/or software – install a new PC, fix a printer, service a cell tower antenna
-
Security personnel ensuring security protocols are followed; e.g., access controls
As above, the primary thing that operations does not do is develop new systems functionality. Operations is process-driven and systematic and tends to be interrupt-driven, whereas R&D fails the “systematic” part of the definition (review the definitions in process, product, and project management). However, new functionality usually has operational impacts. In manufacturing and other traditional industries, product development was a minority of work, while operations was where the bulk of work happened. Yet when an operational task involving information becomes well-defined and repetitive, it can be automated with a computer.
This continuous cycle of innovation and commoditization has driven closer and closer ties between “development” and “operations”. This cycle has also driven confusion around exactly what is meant by “operations”. In many organizations there is an I&O function. Pay close attention to the naming. A matrix may help because we have two dimensions to consider here; see Application, Infrastructure, Development, Operations.
| Development Phase | Operations Phase | |
|---|---|---|
Application Layer |
Application developers. Handle demand, proactive and reactive, from product and operations. Never under I&O. |
Help desk. Application support and maintenance (provisioning, fixes not requiring software development). Often under I&O. |
Infrastructure Layer |
Engineering team. Infrastructure platform engineering and development (design and build typically of externally sourced products). Often under I&O. |
Operations center. Operational support, including monitoring system status. May monitor both infrastructure and application layers. Often under I&O. |
Notice that we distinguish carefully between the application and infrastructure layers. This document using the following pragmatic definitions:
-
Applications are consumed by people who are not primarily concerned with IT
-
Infrastructure is consumed by people who are primarily concerned with IT
Infrastructure services and/or products, as discussed in Digital Infrastructure, need to be designed and developed before they are operated, just like applications. This may all seem obvious, but there is an industry tendency to lump three of the four cells in the table into the I&O function when, in fact, each represents a distinct set of concerns.
The Concept of “Service Level”
Either a digital system is available and providing a service, or it is not. The concept of “service level” was mentioned above by Limoncelli et al. A service level is typically defined in terms of criteria such as:
-
What percentage of the time will the service be available?
-
If the service suffers an outage, how long until it will be restored?
-
How fast will the service respond to requests?
-
At what time will a given task or workload be completed?
An SLA, is a form of contract between the service consumer and service provider, stating the above criteria in terms of a business agreement. When a service’s performance does not meet the agreement, this is sometimes called a “breach” and the service provider may have to pay a penalty (e.g., the customer gets a 5% discount on that month’s services). If the service provider exceeds the SLA, perhaps a credit will be issued.
SLAs drive much operational behavior. They help prioritize incidents and problems, and the risk of proposed changes are understood in terms of the SLAs.
State and Configuration
In all of IT (whether “infrastructure” or “applications”) there is a particular concern with managing state. IT systems are remarkably fragile. One incorrect bit of information – a “0” instead of a “1” – can completely alter a system’s behavior, to the detriment of business operations depending on it.
Therefore, any development of IT – starting with the initial definition of the computing platform – depends on the robust management state.
The following are examples of state:
-
The name of a particular server
-
The network address of that server
-
The software installed on that server, in terms of the exact version and bits that comprise it
State also has more transient connotations:
-
The current processes listed in the process table
-
The memory allocated to each process
-
The current users logged into the system
Finally, we saw in the previous section some server/application/business mappings. These are also a form of state.
It is therefore not possible to make blanket statements like “we need to manage state”. Computing devices go through myriads of state changes with every cycle of their internal clock. (Analog and quantum computing are out of scope for this document.)
The primary question in managing state is “what matters”? What aspects of the system need to persist, in a reliable and reproducible manner? Policy-aware tools are used extensively to ensure that the system maintains its configuration, and that new functionality is constructed (to the greatest degree possible) using consistent configurations throughout the digital pipeline.
Environments
“Production” is a term that new IT recruits rapidly learn has forbidding connotations. To be “in production” means that the broader enterprise value stream is directly dependent on that asset. How do things get to be “in production”? What do we mean by that?
Consider the fundamental principle that there is an IT system delivering some “moment of truth” to someone. This system can be of any scale, but as above we are able to conceive of it having a “state”. When we want to change the behavior of this system, we are cautious. We reproduce the system at varying levels of fidelity (building “lower” environments with Infrastructure as Code techniques) and experiment with potential state changes. This is called development. When we start to gain confidence in our experiments, we increase the fidelity and also start to communicate more widely that we are contemplating a change to the state of the system. We may increase the fidelity along a set of traditional names; see Example Environment Pipeline:
-
Development
-
Build & Test
-
Quality Assurance (QA)
-
Performance (or load) testing
-
Integration
-
Patch
-
Production
The final state, where value is realized, is “production”. Moving functionality in smaller and smaller batches, with increasing degrees of automation, is called continuous delivery.
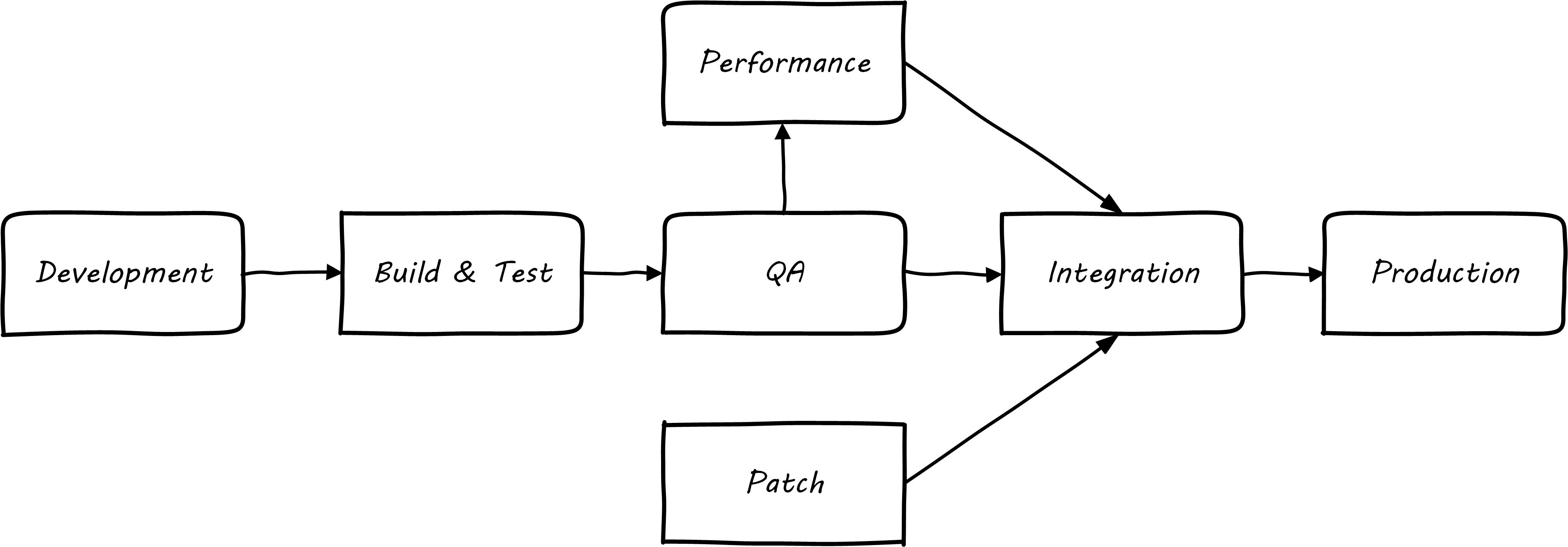
The fundamental idea that new system functionality sequentially moves (“promotes”) through a series of states to gain confidence before finally changing the state of the production system is historically well established. You will see many variations, especially at scale, on the environments listed above. However, the production state is notoriously difficult to reproduce fully, especially in highly distributed environments. While Infrastructure as Code has simplified the problem, lower environments simply cannot match production completely in all its complexity, especially interfaced interactions with other systems or when large, expensive pools of capacity are involved. Therefore there is always risk in changing the state of the production system. Mitigating strategies include:
-
Extensive automated test harnesses that can quickly determine if system behavior has been unfavorably altered
-
Ensuring that changes to the production system can be easily and automatically reversed; for example, code may be deployed but not enabled until a “feature toggle” is set – this allows a quick shutdown of that code if issues are seen
-
Increasing the fidelity of lower environments with strategies such as service virtualization to make them behave more like production
-
Hardening services against their own failure in production, or the failure of services on which they depend
-
Reducing the size (and therefore complexity and risk) of changes to production (a key DevOps/continuous delivery strategy); variations here include:
-
Small functional changes (“one line of code”)
-
Small operational changes (deploying a change to just one node out of 100, and watching it, before deploying to the other 99 nodes)
-
-
Using policy-aware infrastructure management tools
Another important development in environmental approaches is A/B testing or canary deployments. In this approach, the “production” environment is segregated into two or more discrete states, with different features or behaviors exposed to users in order to assess their reactions. Netflix uses this as a key tool for product discovery, testing the user reaction to different user interface techniques, for example. Canary deployments are when a change is deployed to a small fraction of the user base, as a pilot.
Environments as Virtual Concepts
The concept of “environment” can reinforce functional silos and waterfall thinking, and potentially the waste of fixed assets. Performance environments (that can emulate production at scale) are particularly in question.
Instead, in a digital infrastructure environment (private or public), the kind of test you want to perform is defined and that capacity is provisioned on-demand.
“Development is Production”
It used to be that the concept of “testing in production” was frowned upon. Now, with these mitigating strategies, and the recognition that complex systems cannot ever be fully reproduced, there is more tolerance for the idea. But with older systems that may lack automated testing, incremental deployment, or easy rollback, it is strongly recommended to retain existing promotion strategies, as these are battle-tested and known to reduce risk. Often, their cycle time can be decreased.
On the other hand, development systems must never be treated casually:
-
The development pipeline itself represents a significant operational commitment
-
The failure of a source code repository, if not backed up, could wipe out a company [Marks 2014]
-
The failure of a build server or package repository could be almost as bad
-
In the digital economy, dozens or hundreds of developers out of work represents a severe operational and financial setback, even if the “production” systems continue to function
It is, therefore, important to treat “development” platforms with the same care as production systems. This requires nuanced approaches: with Infrastructure as Code, particular virtual machines or containers may represent experiments, expected to fail often and be quickly rebuilt. No need for burdensome change processes when virtual machine base images and containers are being set up and torn down hundreds of times each day! However, the platforms supporting the instantiation and teardown of those virtual machines are production platforms, supporting the business of new systems development.
Evidence of Notability
Operations management is a broad topic in management and industrial theory, with dedicated courses of study and postgraduate degrees. The intersection of operations management and digital systems has been a topic of concern since the first computers were developed and put into use for military, scientific, and business applications.
Limitations
Operations is repeatable, interrupt-driven, and concerned with maintaining a given state of performance. It is usually rigorously distinguished from R&D.
Related Topics