Virtualization
Virtualization Basics
Description
Assume a simple, physical computer such as a laptop. When the laptop is first turned on, the OS loads; the OS is itself software, but is able to directly control the computer’s physical resources: its Central Processing Unit (CPU), memory, screen, and any interfaces such as Wi-Fi®, USB, and Bluetooth®. The OS (in a traditional approach) then is used to run “applications” such as web browsers, media players, word processors, spreadsheets, and the like. Many such programs can also be run as applications within the browser, but the browser still needs to be run as an application.
In the simplest form of virtualization, a specialized application known as a hypervisor is loaded like any other application. The purpose of this hypervisor is to emulate the hardware computer in software. Once the hypervisor is running, it can emulate any number of “virtual” computers, each of which can have its own OS (see Virtualization is Computers Within a Computer). The hypervisor mediates the “virtual machine” access to the actual, physical hardware of the laptop; the virtual machine can take input from the USB port, and output to the Bluetooth interface, just like the master OS that launched when the laptop was turned on.
There are two different kinds of hypervisors. The example we just discussed was an example of a Type 2 hypervisor, which runs on top of a host OS. In a Type 1 hypervisor, a master host OS is not used; the hypervisor runs on the “bare metal” of the computer and in turn “hosts” multiple virtual machines.
Paravirtualization, e.g., containers, is another form of virtualization found in the marketplace. In a paravirtualized environment, a core OS is able to abstract hardware resources for multiple virtual guest environments without having to virtualize hardware for each guest. The benefit of this type of virtualization is increased Input/Output (I/O) efficiency and performance for each of the guest environments. Another benefit is that containers are lightweight and while they can run multiple apps, the idiomatic approach to using them is one app per container and libraries are scoped to each container. This eliminates the issues that stem from shared libraries, as illustrated in Virtualization is Computers Within a Computer.
However, while hypervisors can support a diverse array of virtual machines with different OSs on a single computing node, guest environments in a paravirtualized system generally share a single OS; see Virtualization Types for an overview of all the types.
Virtualization and Efficiency
Virtualization attracted business attention as a means to consolidate computing workloads. For years, companies would purchase servers to run applications of various sizes, and in many cases the computers were badly underutilized. Because of configuration issues and (arguably) an overabundance of caution, average utilization in a pre-virtualization data center might average 10-20%; i.e., up to 90% of the computer’s capacity being wasted; see Inefficient Utilization.

Inefficient Utilization is a simplification. Computing and storage infrastructure supporting each application stack in the business were sized to support each workload. For example, a payroll server might run on a different infrastructure configuration than a Data Warehouse (DW) server. Large enterprises needed to support hundreds of different infrastructure configurations, increasing maintenance, and support costs.
The adoption of virtualization allowed businesses to compress multiple application workloads onto a smaller number of physical servers; see Efficiency through Virtualization.
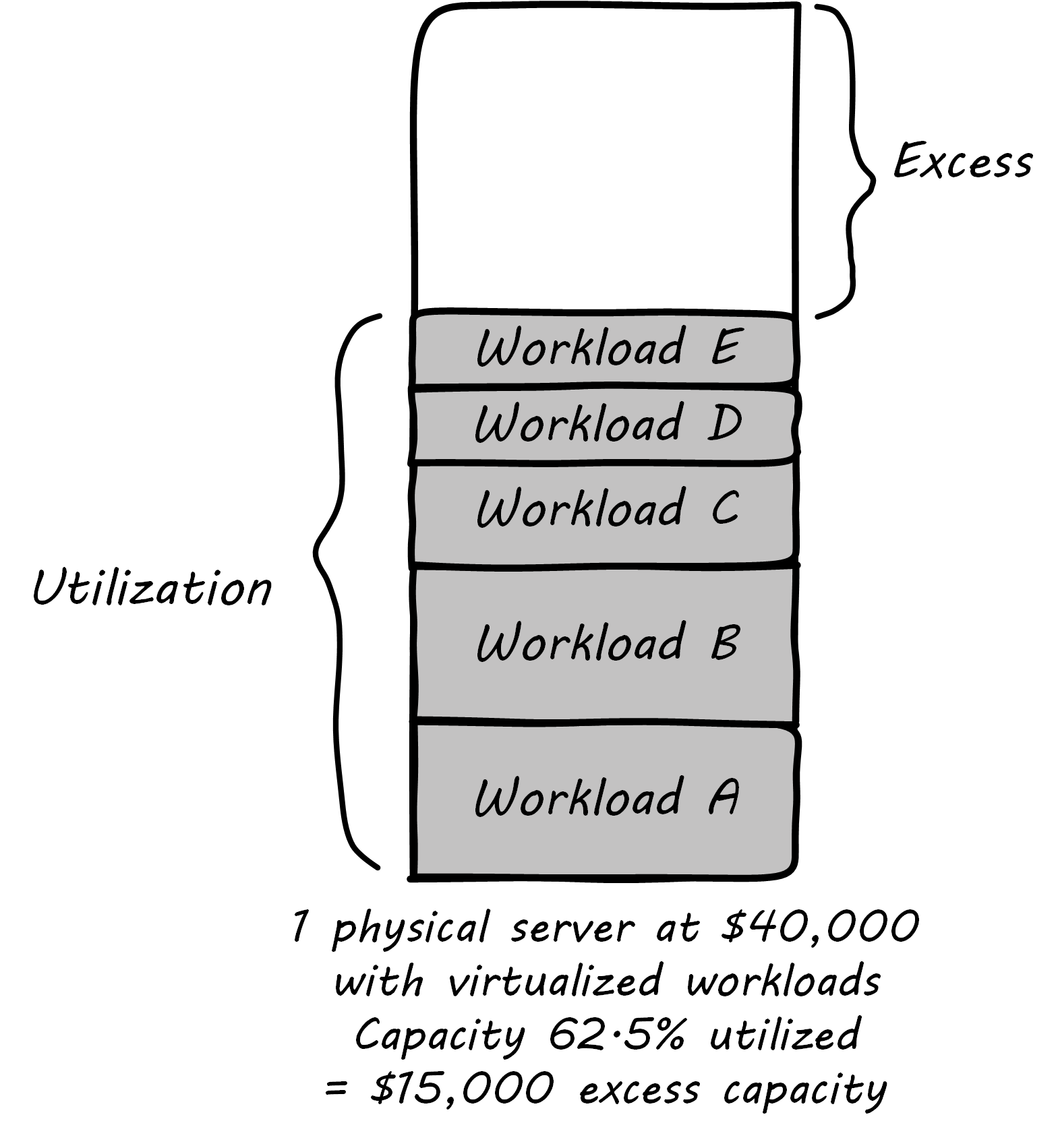
| For illustration only. A utilization of 62.5% might actually be a bit too high for comfort, depending on the variability and criticality of the workloads. |
In most virtualized architectures, the physical servers supporting workloads share a consistent configuration, which makes it easy to add and remove resources from the environment. The virtual machines may still vary greatly in configuration, but the fact of virtualization makes managing that easier – the virtual machines can be easily copied and moved, and increasingly can be defined as a form of code.
Virtualization thus introduced a new design pattern into the enterprise where computing and storage infrastructure became commoditized building blocks supporting an ever-increasing array of services. But what about where the application is large and virtualization is mostly overhead? Virtualization still may make sense in terms of management consistency and ease of system recovery.
Container Management and Kubernetes
Containers (paravirtualization) have emerged as a powerful and convenient technology for managing various workloads. Architectures based on containers running in cloud platforms, with strong Application Programming Interface (API) provisioning and integrated support for load balancing and autoscaling, are called “cloud-native”. The perceived need for a standardized control plane for containers resulted in various initiatives in the 2010s: Docker Swarm™, Apache Mesos®, and (emerging as the de facto standard) Kubernetes® from the Cloud Native Computing Foundation® (CNCF®).
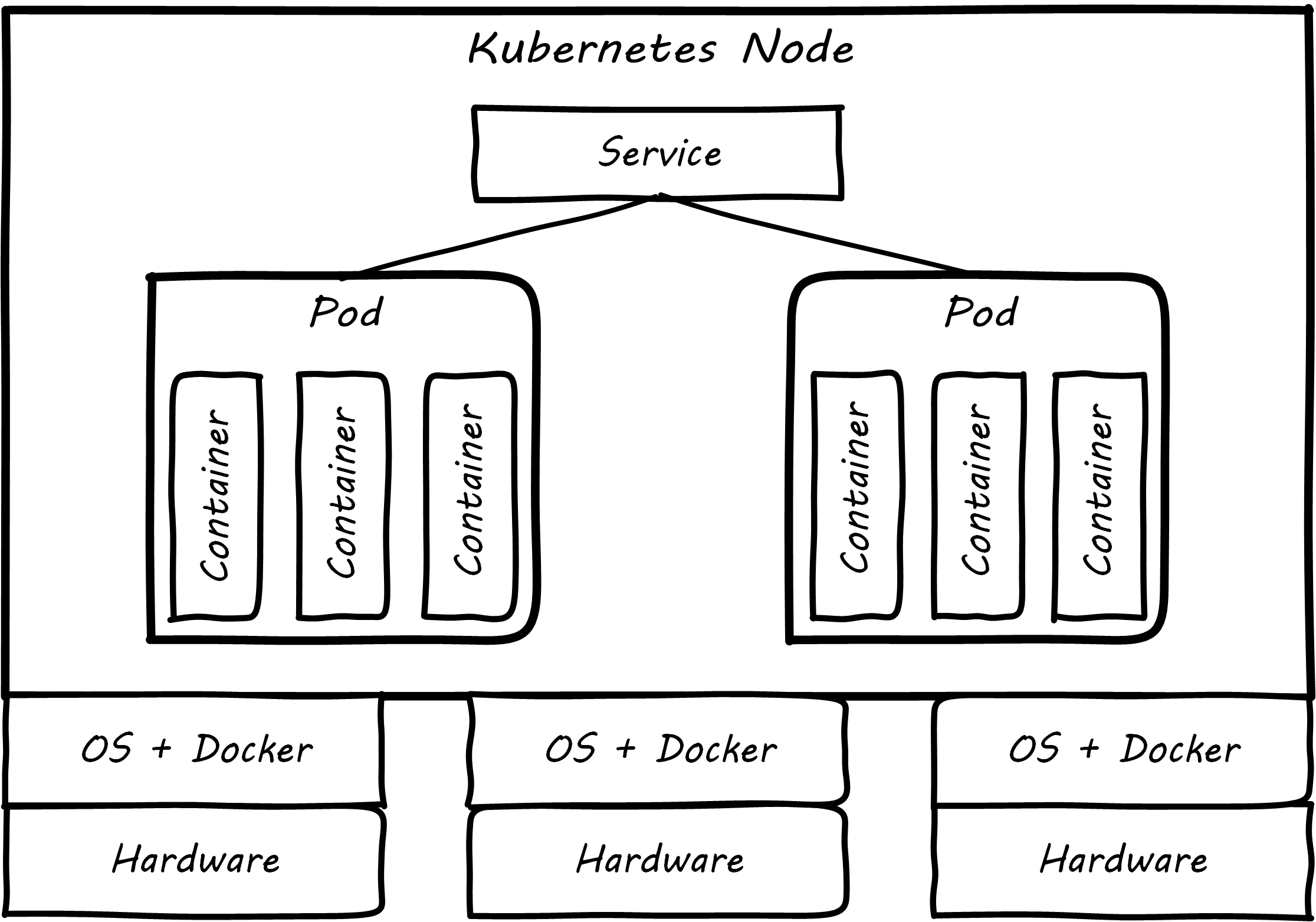
Kubernetes is an open source orchestration platform based on the following primitives (see Kubernetes Infrastructure, Pods, and Services):
-
Pods: group containers
-
Services: a set of pods supporting a common set of functionality
-
Volumes: define persistent storage coupled to the lifetime of pods (therefore lasting across container lifetimes, which can be quite brief)
-
Namespaces: in Kubernetes (as in computing generally) provide mutually-exclusive labeling to partition resources
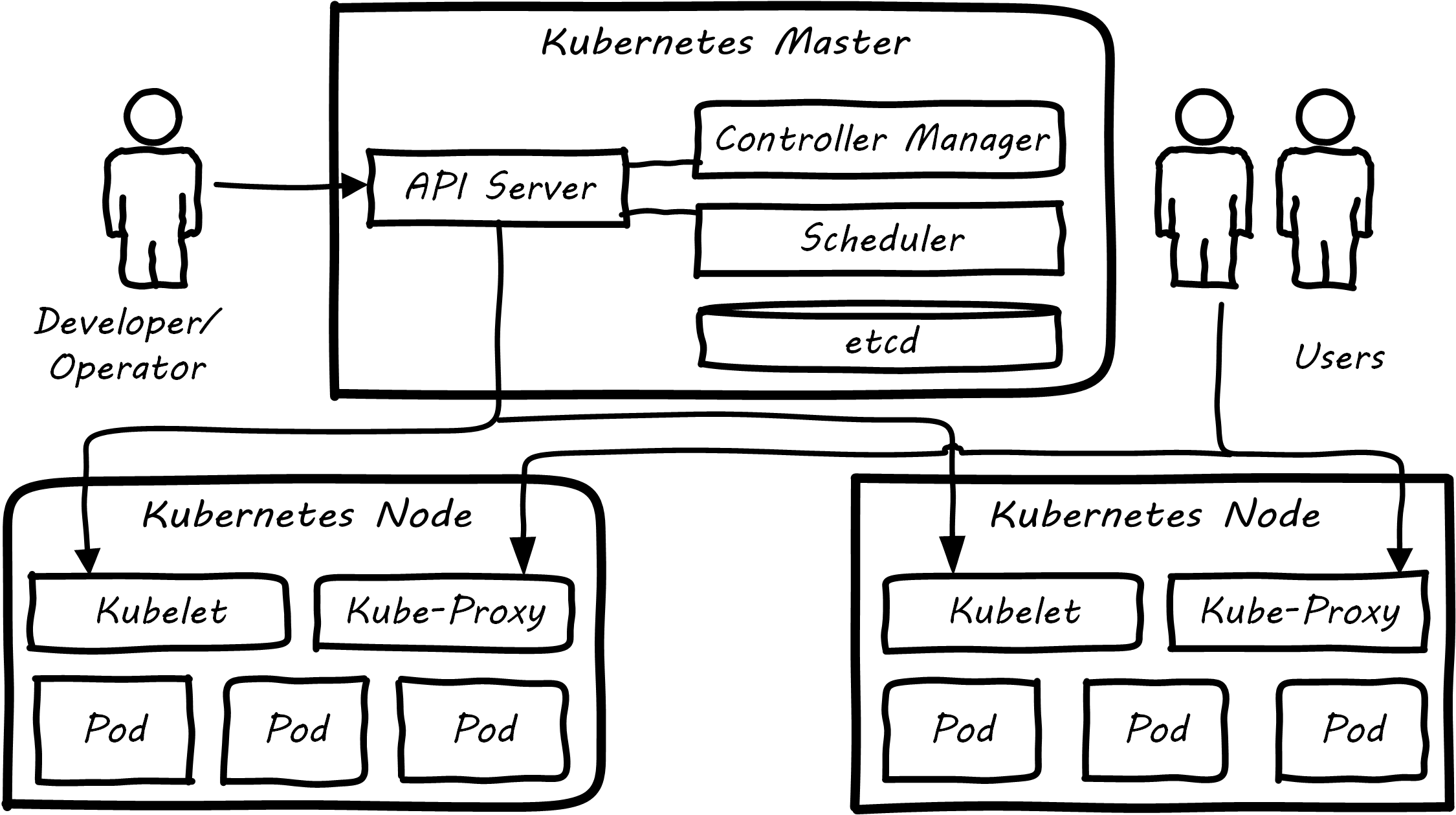
Kubernetes management (see Kubernetes Cluster Architecture) is performed via a Master controller which supervises the nodes. This consists of:
-
API server: the primary communication point for provisioning and control requests
-
Controller manager: implements declarative functionality, in which the state of the cluster is managed against policies; the controller seeks to continually converge the actual state of the cluster with the intended (policy-specified) state; see Imperative and Declarative
-
Scheduler: manages the supply of computing resources to the stated (policy-drive) demand
The nodes run:
-
Kubelet for managing nodes and containers
-
Kube-proxy for services and traffic management
Much other additional functionality is available and under development; the Kubernetes ecosystem as of 2019 is growing rapidly.
Graphics similar to those presented in Wiki-K8s.
Serverless Computing
Serverless computing is perhaps the ultimate stage in virtualization because it can completely remove any explicit definition of the compute platform. Instead, code and data is submitted to a serverless service and results are returned some time later, but details of the compute platform that executed the code (e.g., specification, location) may be unknown. In practice, most commercial implementations of serverless computing require some declaration of the compute platform characteristics, even if only in the form of capacity limits. In general, the advantages of serverless systems are low cost, speed of deployment, and scaleability. Disadvantages are typically related to performance, because there is usually no guarantee related to start-up times or the power of the actual compute platform allocated at runtime.
Competency Category “Virtualization” Example Competencies
-
Install and configure a virtual machine
-
Configure several virtual machines to communicate with each other
Evidence of Notability
Virtualization was predicted in the earliest theories that led to the development of computers. Turing and Church realized that any general-purpose computer could emulate any other. Virtual systems have existed in some form since at latest 1967 – only 20 years after the first fully functional computers.
Virtualization is discussed extensively in core computer science and engineering texts and is an essential foundation of cloud computing.
The cloud-native community is, at the time of writing, one of the most active communities in computing.
Limitations
Virtualization is mainly relevant to production computing. It is less relevant to edge devices.
Related Topics