Operational Response
Description
Monitoring communicates the state of the digital systems to the professionals in charge of them. Acting on that telemetry involves additional tools and practices, some of which we will review in this section.
Communication Channels
When signals emerge from the lower levels of the digital infrastructure, they pass through a variety of layers and cause assorted, related behaviors among the responsible Digital Practitioners. The accompanying illustration shows a typical hierarchy, brought into action as an event becomes apparently more significant; see Layered Communications Channels.
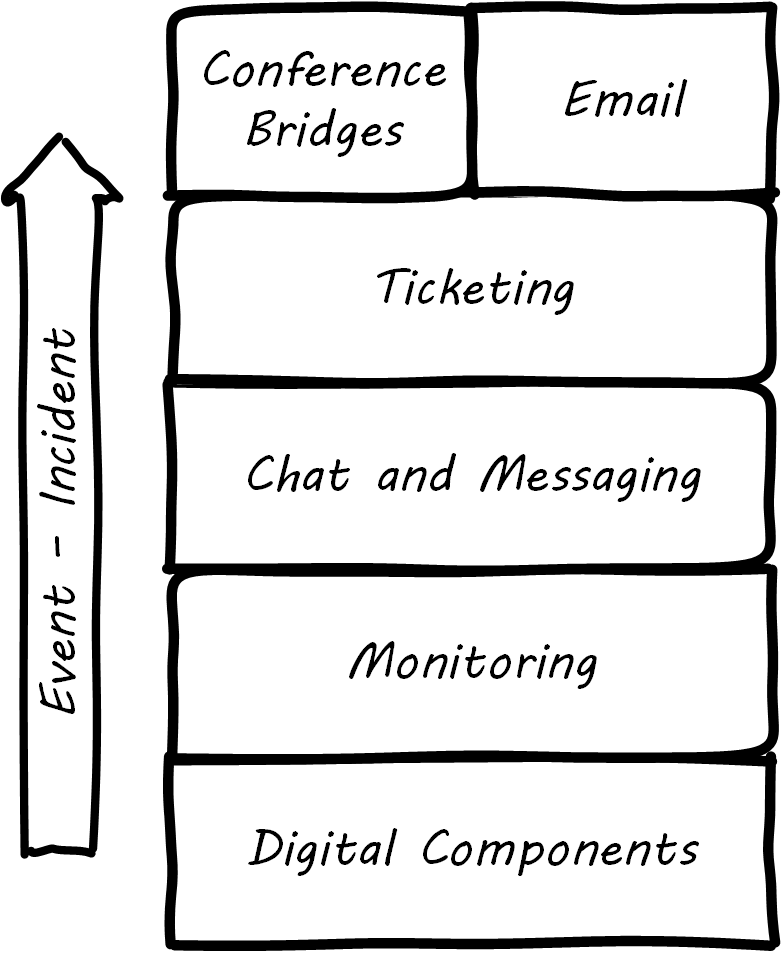
The digital components send events to the monitoring layer, which filters them for significant concerns; for example, a serious application failure. The monitoring tool might automatically create a ticket, or perhaps it first provides an alert to the system’s operators, who might instant message each other, or perhaps join a chatroom.
If the issue cannot be resolved operationally before it starts to impact users, an Incident ticket might be created, which has several effects:
-
First, the situation is now a matter of record, and management may start to pay attention
-
Accountability for managing the incident is defined, and expectations are that responsible parties will start to resolve it
-
If assistance is needed, the incident provides a common point of reference (it is a common reference point), in terms of work management
Depending on the seriousness of the incident, further communications by instant messaging, chat, cell phone, email, and/or conference bridge may continue. Severe incidents in regulated industries may require recording of conference bridges.
ChatOps is the tight integration of instant communications with operational execution. In a chatroom, a virtual agent or “bot” is enabled and monitors the human-to-human interactions. The human beings can issue certain commands to the bot, such as code deployments, team notifications, server restarts, or more [Sigler 2014].
Properly configured ChatOps provides a low-friction collaborative environment, enabling a powerful and immediate collective mental model of the situation and what is being done. It also provides a rich audit trail of who did what, when, and who else was involved. Fundamental governance objectives of accountability can be considered fulfilled in this way, on a par with paper or digital forms routed for approval (and without their corresponding delays).
Operational Process Emergence
Process is what makes it possible for teams to do the right thing, again and again. [Limoncelli et al. 2014]
Limoncelli et al., in their excellent Cloud Systems Administration, emphasize the role of the “oncall” and “onduty” staff in the service of operations. Oncall staff have a primary responsibility of emergency response, and the term on call refers to their continuous availability, even if they are not otherwise working (e.g., they are expected to pick up phone calls and alerts at home and dial into emergency communications channels). Onduty staff are responsible for responding to non-critical incidents and maintaining current operations.
What is an emergency? It is all a matter of expectations. If a system (by its SLA) is supposed to be available 24 hours a day, 7 days a week, an outage at 3.00am Saturday morning is an emergency. If it is only supposed to be available from Monday through Friday, the outage may not be as critical (although it still needs to be fixed in short order, otherwise there will soon be an SLA breach!).
IT systems have always been fragile and prone to malfunction. “Emergency” management is documented as a practice in “data processing” as early as 1971 [Ditri et al. 1971]. In Competency Area 5, we discussed how simple task management starts to develop into process management. Certainly, there is a concern for predictability when the objective is to keep a system running, and so process management gains strength as a vehicle for structuring work. By the 1990s, a process terminology was increasingly formalized, by vendors such as IBM (in their “Yellow Book” series), the UK’s IT Infrastructure Library (ITIL), and other guidance such as the Harris Kern library (popular in the US before ITIL gained dominance). These processes include:
-
Request management
-
Incident management
-
Problem management
-
Change management
Even as a single-product team, these processes are a useful framework to keep in mind as operational work increases. See Basic Operational Processes for definitions of the core processes usually first implemented.
| Process | Definition |
|---|---|
Request management |
Respond to routine requests such as providing systems access. |
Incident management |
Identify service outages and situations that could potentially lead to them, and restore service and/or mitigate immediate risk. |
Problem management |
Identify the causes of one or more incidents and remedy them (on a longer-term basis). |
Change management |
Record and track proposed alterations to critical IT components. Notify potentially affected parties and assess changes for risk; ensure key stakeholders exercise approval rights. |
These processes have a rough sequence to them:
-
Give the user access to the system
-
If the system is not functioning as expected, identify the issue and restore service by any means necessary – do not worry about why it happened yet
-
Once service is restored, investigate why the issue happened (sometimes called a post-mortem) and propose longer-term solutions
-
Inform affected parties of the proposed changes, collect their feedback and approvals, and track the progress of the proposed change through successful completion
At the end of the day, we need to remember that operational work is just one form of work. In a single-team organization, these processes might still be handled through basic task management (although user provisioning would need to be automated if the system is scaling significantly). It might be that the simple task management is supplemented with checklists since repeatable aspects of the work become more obvious. We will continue on the assumption of basic task management for the remainder of this Competency Area, and go deeper into the idea of defined, repeatable processes as we scale to a “team of teams” in Context III.
Post-Mortems, Blamelessness, and Operational Demand
It is important to start from the principle that people are not operating in a negligent manner; they are just lacking the context to make the better decisions. [Blank-Edelman 2018]
We briefly mentioned problem management as a common operational process. After an incident is resolved and services are restored, further investigation (sometimes called “root cause analysis”) is undertaken as to the causes and long-term solutions to the problem. This kind of investigation can be stressful for the individuals concerned and human factors become critical.
| The term “root cause analysis” is viewed by some as misleading, as complex system failures often have multiple causes. Other terms are post-mortems or simply causal analysis. |
We have discussed psychological safety previously. Psychological safety takes on an additional and even more serious aspect when we consider major system outages, many of which are caused by human error. There has been a long history of management seeking individuals to “hold accountable” when complex systems fail. This is an unfortunate approach, as complex systems are always prone to failure. Cultures that seek to blame do not promote a sense of psychological safety.
The definition of “counterfactual” is important. A “counterfactual” is seen in statements in the form of “if only Joe had not re-indexed the database, then the outage would not have happened”. It may be true that if Joe had not done so, the outcome would have been different. But there might be other such counterfactuals. They are not helpful in developing a continual improvement response. The primary concern in assessing such a failure is “how was Joe put in a position to fail?”. Put differently, how is it that the system was designed to be vulnerable to such behavior on Joe’s part? How could it be designed differently, and in a less sensitive way?
This is, in fact, how aviation has become so safe. Investigators with the unhappy job of examining large-scale airplane crashes have developed a systematic, clinical, and rational approach for doing so. They learned that if the people they were questioning perceived a desire on their part to blame, the information they provided was less reliable. (This, of course, is obvious to any parent of a four-year old.)
John Allspaw, CTO of Etsy, has pioneered the application of modern safety and incident investigation practices in digital contexts and notably has been an evangelist for the work of human factors expert and psychologist Sidney Dekker. Dekker summarizes attitudes towards human error as falling into either the old or new views. He summarizes the old view as the Bad Apple theory:
-
Complex systems would be fine, were it not for the erratic behavior of some unreliable people (Bad Apples) in it
-
Human errors cause accidents: humans are the dominant contributor to more than two thirds of them
-
Failures come as unpleasant surprises; they are unexpected and do not belong in the system – failures are introduced to the system only through the inherent unreliability of people
Dekker contrasts this with the new view:
-
Human error is not a cause of failure – human error is the effect, or symptom, of deeper trouble
-
Human error is not random – it is systematically connected to features of people’s tools, tasks, and operating environment
-
Human error is not the conclusion of an investigation; it is the starting point [Dekker 2014]
Dekker’s principles are an excellent starting point for developing a culture that supports blameless investigations into incidents. We will talk more systematically of culture in Coordination and Process.
Finally, once a post-mortem or problem analysis has been conducted, what is to be done? If work is required to fix the situation (and when is it not?), this work will compete with other priorities in the organization. Product teams typically like to develop new features, not solve operational issues that may call for reworking existing features. Yet serving both forms of work is essential from a holistic, design thinking point of view.
In terms of queuing, operational demand is too often subject to the equivalent of queue starvation – which as Wikipedia notes is usually the result of “naive scheduling algorithms”. If we always and only work on what we believe to be the “highest priority” problems, operational issues may never get attention. One result of this is the concept of technical debt, which we discuss in Context IV.
Drills, Game Days, and Chaos Engineering
As noted above, it is difficult to fully reproduce complex production infrastructures as “lower” environments. Therefore, it is difficult to have confidence in any given change until it has been run in production.
The need to emulate “real-world” conditions is well understood in the military, which relies heavily on drills and exercises to ensure peak operational readiness. Analogous practices are emerging in digital organizations, such as the concept of “Game Days” – defined periods when operational disruptions are simulated and the responses assessed. A related set of tools is the Netflix Simian Army, a collection of resiliency tools developed by the online video-streaming service Netflix. It represents a significant advancement in digital risk management, as previous control approaches were too often limited by poor scalability or human failure (e.g., forgetfulness or negligence in following manual process steps).
Chaos Monkey is one of a number of tools developed to continually “harden” the Netflix system, including:
-
Latency Monkey – introduces arbitrary network delays
-
Conformity Monkey – checks for consistency with architectural standards, and shuts down non-conforming instances
-
Doctor Monkey – checks for longer-term evidence of instance degradation
-
Janitor Monkey – checks for and destroys unused running capacity
-
Security Monkey – an extension of Conformity Monkey, checks for correct security configuration
-
10-18 Monkey – checks internationalization
-
Finally, Chaos Gorilla simulates the outage of an entire Amazon availability zone
On the whole, the Simian Army behaves much as antibodies do in an organic system. One notable characteristic is that the monkeys as described do not generate a report (a secondary artifact) for manual follow-up. They simply shut down the offending resources.
Such direct action may not be possible in many environments but represents an ideal to work toward. It keeps the security and risk work “front and center” within the mainstream of the digital pipeline, rather than relegating it to the bothersome “additional work” it can so easily be seen as.
A new field of chaos engineering is starting to emerge centered on these concepts.
Site Reliability Engineering
SRE is a practice for operations-centric work with a focus on automation and reliability. It originates from Google and other large digital organizations. SRE is an operational discipline; an SRE team is responsible for the “availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning of their service” [Beyer et al. 2016].
Site reliability engineers have strong technical backgrounds, frequently computer science, and with experience in software engineering, which is atypical for operations staff in the traditional IT industry. SREs are strongly incented to automate as much as possible to replace manual operations with software, for example to codify “toil” tasks (i.e., repetitive, non-value-add tasks) or common error recovery tasks. In other words, as Benjamin Sloss says: “we want systems that are automatic, not just automated” [Beyer et al. 2016].
Google pioneered a number of innovative practices with its SRE team, including:
-
A 50% cap on aggregate “ops” work – the other 50% is supposed to be spent on development
-
The concept of an “error budget” as a control mechanism – teams are incented not for “zero downtime” but rather to take the risk and spend the error budget
-
“Release Engineer” as a specific job title for those focused on building and maintaining the delivery pipeline
Evidence of Notability
Identifying the need for and marshaling operational response is an essential capability in managing digital systems.
Limitations
Operational response is typically urgent and time-bound. It is not reflective nor, in general, creative or innovative (except out of necessity).
Related Topics