Configuration Management and Infrastructure as Code
Description
This section covers:
-
Version control
-
Source control
-
Package management
-
Deployment management
-
Configuration management
Managing Infrastructure
Two computers may both run the same version of an OS, and yet exhibit vastly different behaviors. This is due to how they are configured. One may have web-serving software installed; the other may run a database. One may be accessible to the public via the Internet; access to the other may be tightly restricted to an internal network. The parameters and options for configuring general-purpose computers are effectively infinite. Misconfigurations are a common cause of outages and other issues.
In years past, infrastructure administrators relied on the ad hoc issuance of commands either at an operations console or via a Graphical User Interface (GUI) based application. Such commands could also be listed in text files; i.e., “batch files” or “shell scripts” to be used for various repetitive processes, but systems administrators, by tradition and culture, were empowered to issue arbitrary commands to alter the state of the running system directly.
However, it is becoming more and more rare for a systems administrator to actually “log in” to a server and execute configuration-changing commands in an ad hoc manner. Increasingly, all actual server configuration is based on pre-developed specification.
Because virtualization is becoming so powerful, servers increasingly are destroyed and rebuilt at the first sign of any trouble. In this way, it is certain that the server’s configuration is as intended. This again is a relatively new practice.
Previously, because of the expense and complexity of bare-metal servers, and the cost of having them offline, great pains were taken to fix troubled servers. Systems administrators would spend hours or days troubleshooting obscure configuration problems, such as residual settings left by removed software. Certain servers might start to develop “personalities”. Industry practice has changed dramatically here since around 2010.
As cloud infrastructures have scaled, there has been an increasing need to configure many servers identically. Auto-scaling (adding more servers in response to increasing load) has become a widely used strategy as well. Both call for increased automation in the provisioning of IT infrastructure. It is simply not possible for a human being to be hands on at all times in configuring and enabling such infrastructures, so automation is called for.
Sophisticated Infrastructure as Code techniques are an essential part of modern SRE practices such as those used by Google®. Auto-scaling, self-healing systems, and fast deployments of new features all require that infrastructure be represented as code for maximum speed and reliability of creation.
Infrastructure as Code is defined by Kief Morris as: “an approach to infrastructure automation based on practices from software development. It emphasizes consistent, repeatable routines for provisioning and changing systems and their configuration. Changes are made to definitions and then rolled out to systems through unattended processes that include thorough validation” [Morris 2016].
Infrastructure as Code
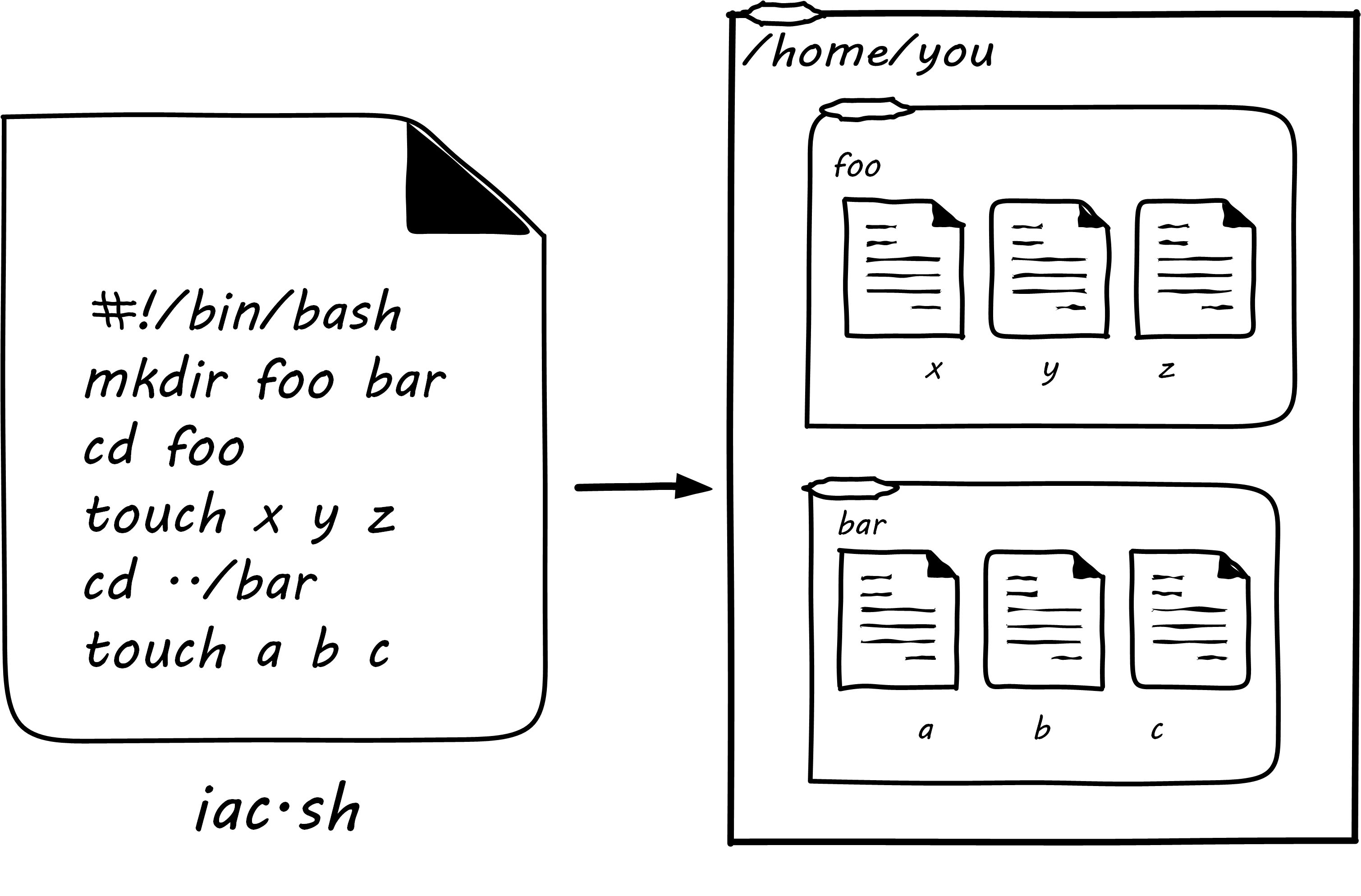
In presenting Infrastructure as Code at its simplest, we will start with the concept of a shell script. Consider the following set of commands:
$ mkdir foo bar $ cd foo $ touch x y z $ cd ../bar $ touch a b c
What does this do? It tells the computer:
-
Create (
mkdir) two directories, one named foo and one named bar -
Move (
cd) to the one named foo -
Create (
touch) three files, named x, y, and z -
Move to the directory named bar
-
Create three blank files, named a, b, and c
A user with the appropriate permissions at a UNIX® or Linux command prompt who runs those commands will wind up with a configuration that could be visualized as in Simple Directory/File Structure Script. Directory and file layouts count as configuration and in some cases are critical.
Assume further that the same set of commands is entered into a text file thus:
#!/bin/bash mkdir foo bar cd foo touch x y z cd ../bar touch a b c
The file might be named iac.sh, and with its permissions set correctly, it could be run so that the computer executes all the commands, rather than a person running them one at a time at the console. If we did so in an empty directory, we would again wind up with that same configuration.
Beyond creating directories and files shell scripts can create and destroy virtual servers and containers, install and remove software, set up and delete users, check on the status of running processes, and much more.
| The state of the art in infrastructure configuration is not to use shell scripts at all but either policy-based infrastructure management or container definition approaches. Modern practice in cloud environments is to use templating capabilities such as AWS™ CloudFormation or HashiCorp Terraform® (which is emerging as a de facto platform-independent standard for cloud provisioning). |
Version Control
Consider again the iac.sh file. It is valuable. It documents intentions for how a given configuration should look. It can be run reliably on thousands of machines, and it will always give us two directories and six files. In terms of the previous section, we might choose to run it on every new server we create. Perhaps it should be established it as a known resource in our technical ecosystem. This is where version control and the broader concept of configuration management come in.
For example, a configuration file may be developed specifying the capacity of a virtual server, and what software is to be installed on it. This artifact can be checked into version control and used to re-create an equivalent server on-demand.
Tracking and controlling such work products as they evolve through change after change is important for companies of any size. The practice applies to computer code, configurations, and, increasingly, documentation, which is often written in a lightweight markup language like Markdown or Asciidoc®. In terms of infrastructure, configuration management requires three capabilities:
-
The ability to back up or archive a system’s operational state (in general, not including the data it is processing – that is a different concern); taking the backup should not require taking the system down
-
The ability to compare two versions of the system’s state and identify differences
-
The ability to restore the system to a previously archived operational state
Version control is critical for any kind of system with complex, changing content, especially when many people are working on that content. Version control provides the capability of seeing the exact sequence of a complex system’s evolution and isolating any particular moment in its history or providing detailed analysis on how two versions differ. With version control, we can understand what changed and when – which is essential to coping with complexity.
While version control was always deemed important for software artifacts, it has only recently become the preferred paradigm for managing infrastructure state as well. Because of this, version control is possibly the first IT management system you should acquire and implement (perhaps as a cloud service, such as GitHub™, Gitlab®, or Bitbucket™).
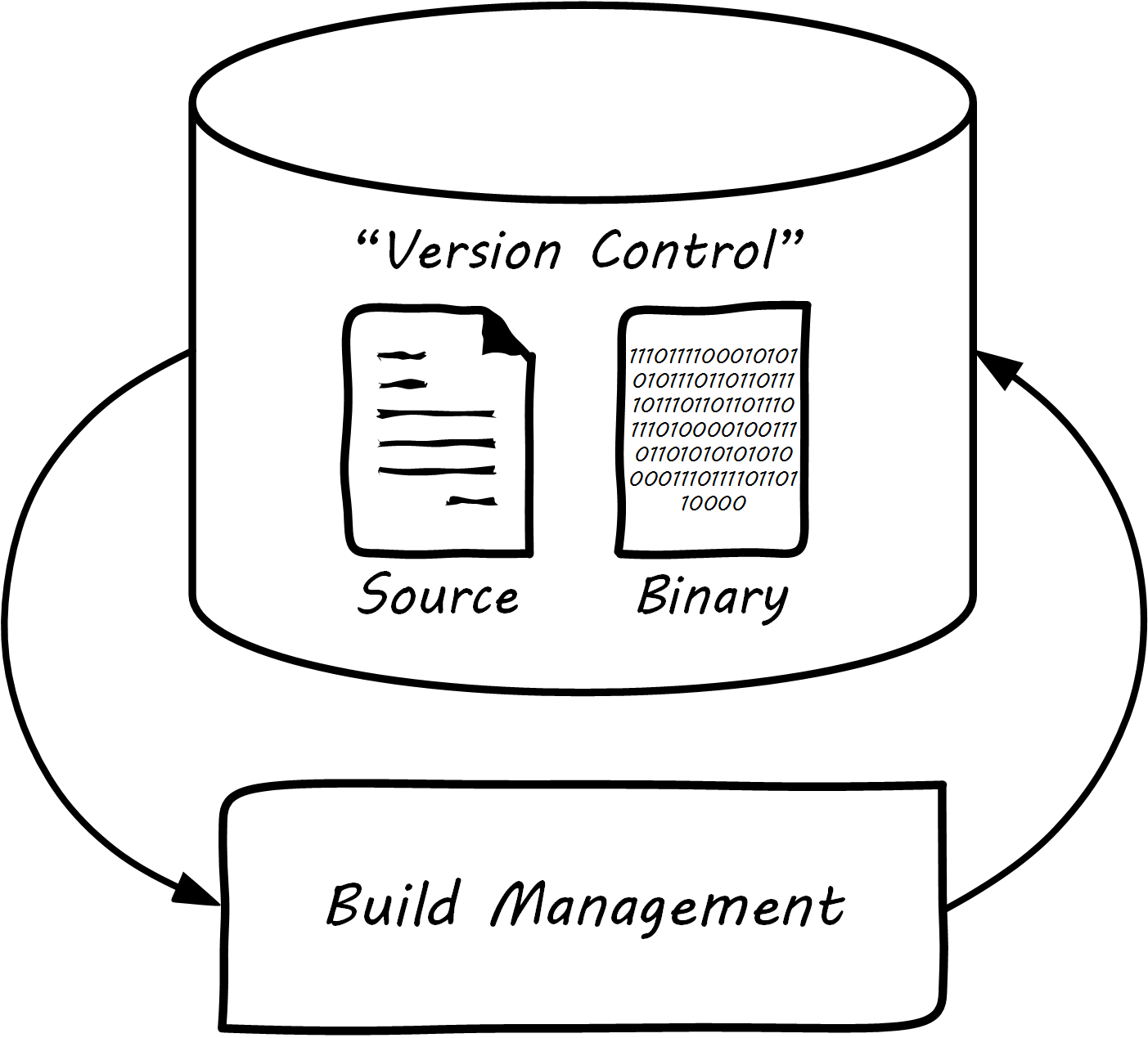
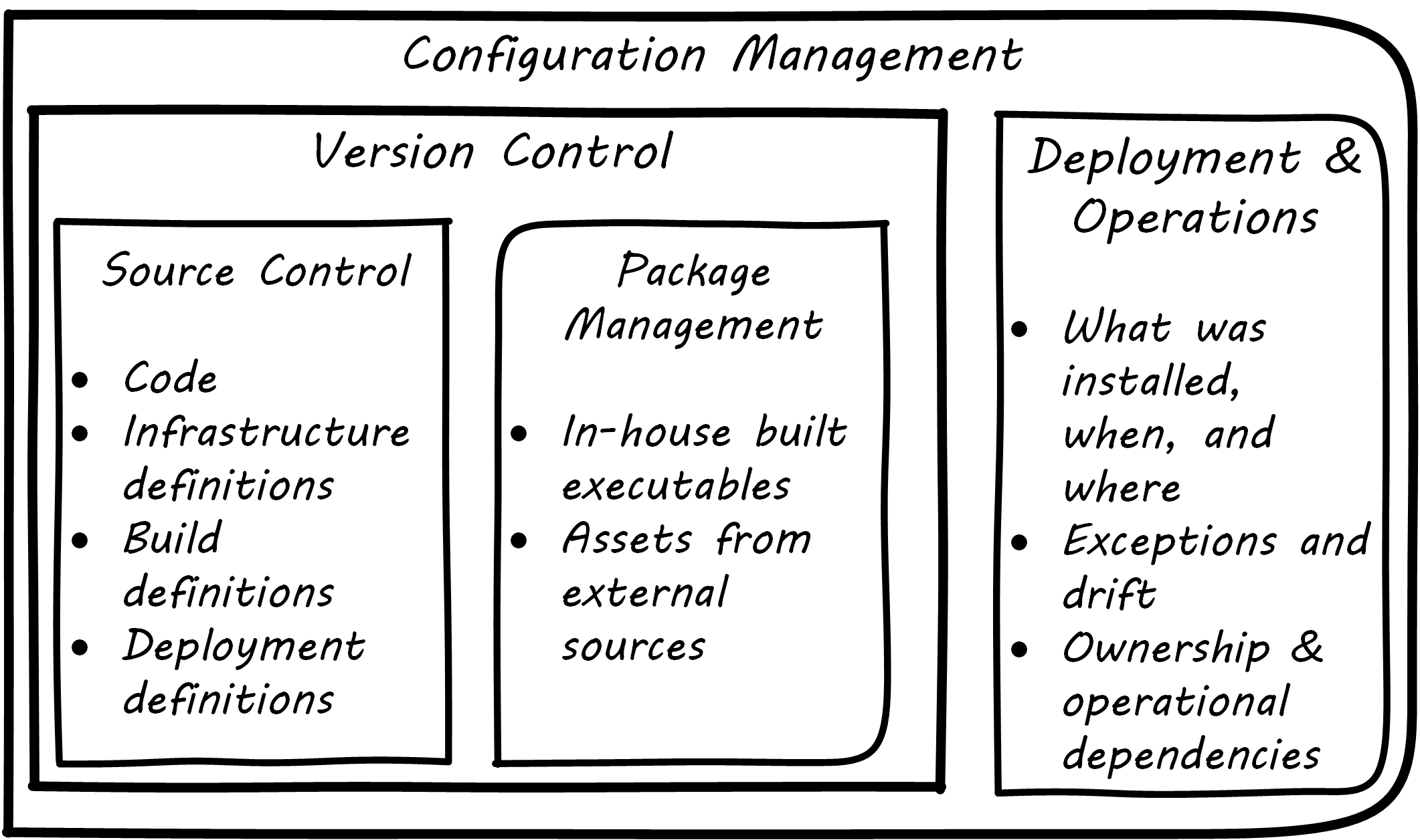
Version control in recent years increasingly distinguishes between source control and package management (see Types of Version Control and Configuration Management and its Components): the management of binary files, as distinct from human-understandable symbolic files. It is also important to understand what versions are installed on what computers; this can be termed “deployment management”. (With the advent of containers, this is a particularly fast-changing area.)
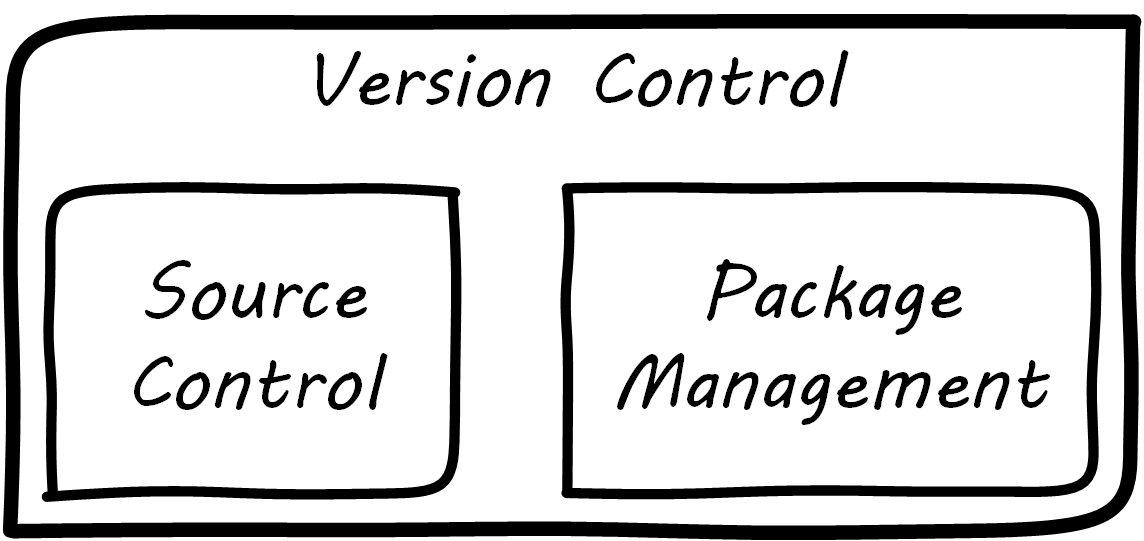
Version control works like an advanced file system with a memory. (Actual file systems that do this are called versioning file systems.) It can remember all the changes you make to its contents, tell you the differences between any two versions, and also bring back the version you had at any point in time.
Survey research presented in the annual State of DevOps report indicates that version control is one of the most critical practices associated with high-performing IT organizations [Brown et al. 2016]. Nicole Forsgren [Forsgren 2016] summarizes the practice of version control as:
-
Our application code is in a version control system
-
Our system configurations are in a version control system
-
Our application configurations are in a version control system
-
Our scripts for automating build and configuration are in a version control system
Source Control
Digital systems start with text files; e.g., those encoded in American Standard Code for Information Interchange (ASCII) or Unicode®. Text editors create source code, scripts, and configuration files. These will be transformed in defined ways (e.g., by compilers and build tools) but the human-understandable end of the process is mostly based on text files. In the previous section, we described a simple script that altered the state of a computer system. We care very much about when such a text file changes. One wrong character can completely alter the behavior of a large, complex system. Therefore, our configuration management approach must track to that level of detail.
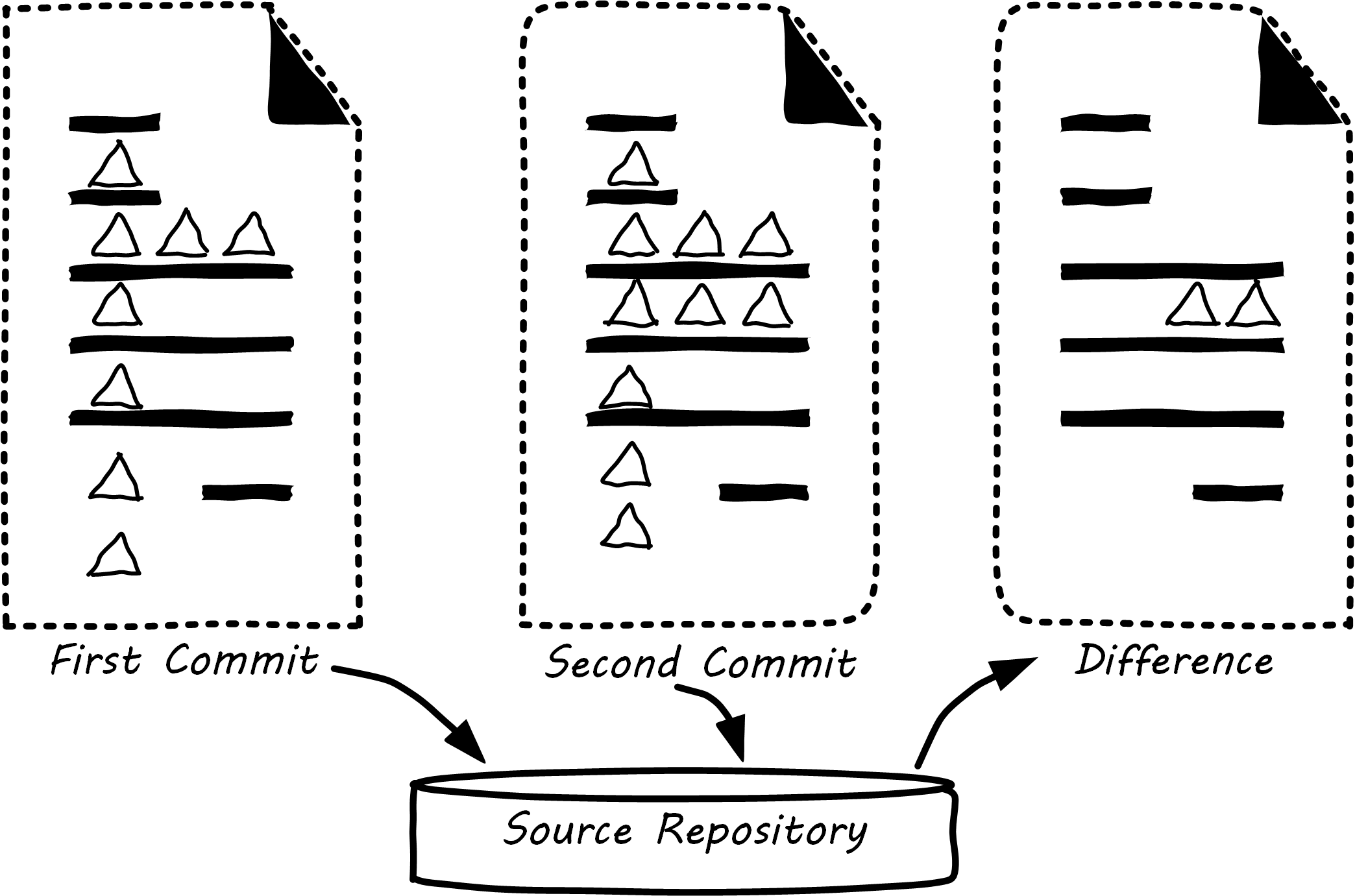
Source control is at its most powerful when dealing with textual data. It is less useful in dealing with binary data, such as image files. Text files can be analyzed for their differences in an easy to understand way (see Source Control). If “abc” is changed to “abd”, then it is clear that the third character has been changed from “c” to “d”. On the other hand, if we start with a digital image (e.g., a .png file), alter one pixel, and compare the result before and after binary files in terms of their data, it would be more difficult to understand what had changed. We might be able to tell that they are two different files easily, but they would look very similar, and the difference in the binary data might be difficult to understand.
The “Commit” Concept
Although implementation details may differ, all version control systems have some concept of “commit”. As stated in Version Control with Git™ [Loeliger & McCullough 2012]: “In Git, a commit is used to record changes to a repository … Every Git commit represents a single, atomic changeset with respect to the previous state. Regardless of the number of directories, files, lines, or bytes that change with a commit … either all changes apply, or none do.” [emphasis added]
The concept of a version or source control “commit” serves as a foundation for IT management and governance. It both represents the state of the computing system as well as providing evidence of the human activity affecting it. The “commit” identifier can be directly referenced by the build activity, which in turn is referenced by the release activity, which typically visible across the IT value chain.
Also, the concept of an atomic “commit” is essential to the concept of a “branch” – the creation of an experimental version, completely separate from the main version, so that various alterations can be tried without compromising the overall system stability. Starting at the point of a “commit”, the branched version also becomes evidence of human activity around a potential future for the system. In some environments, the branch is automatically created with the assignment of a requirement or story. In other environments, the very concept of branching is avoided. The human-understandable, contextual definitions of IT resources is sometimes called metadata.
Package Management
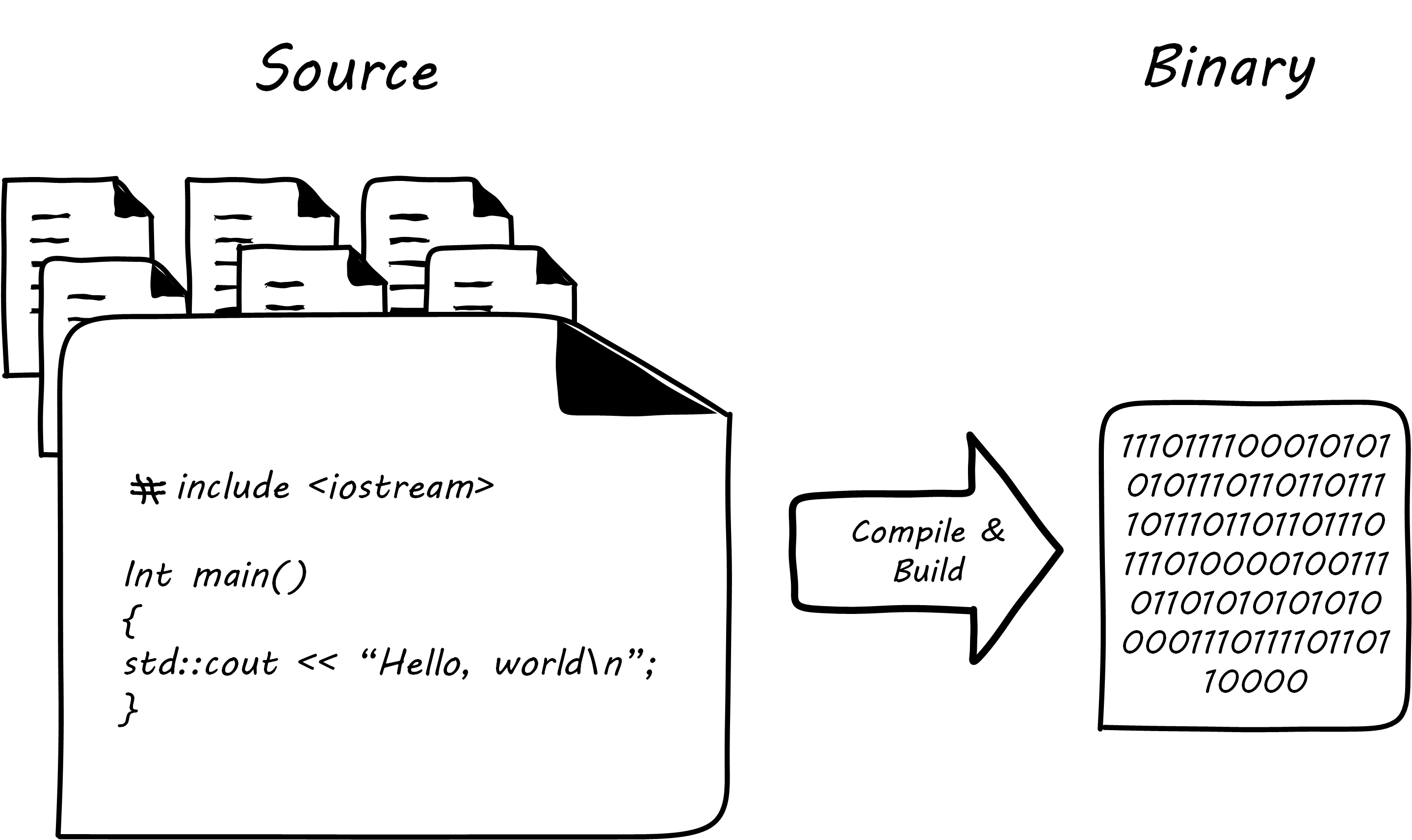
Much if not most software, once created as some kind of text-based artifact suitable for source control, must be compiled and further organized into deployable assets, often called “packages”; see Building Software.
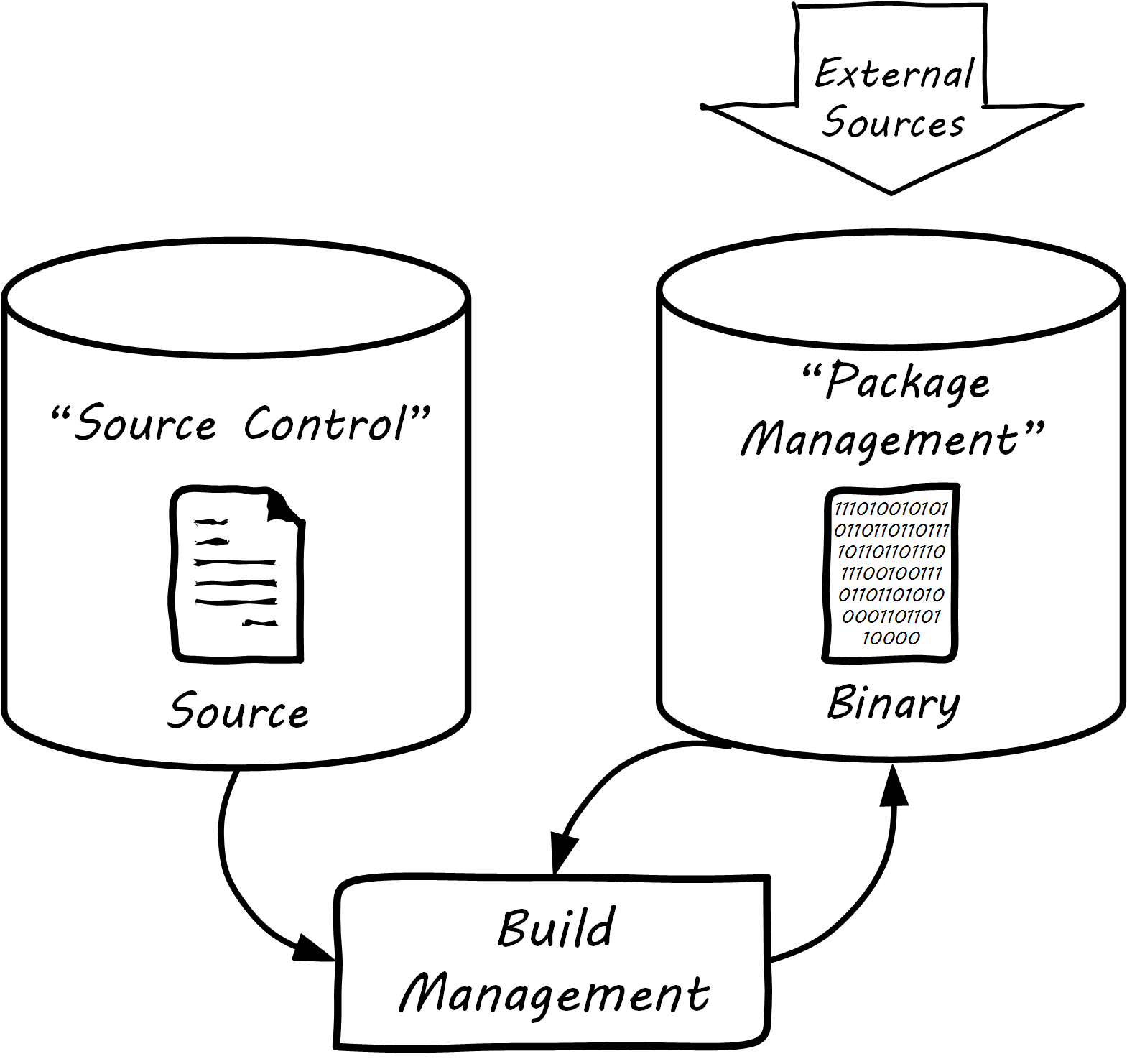
In some organizations, it was once common for compiled binaries to be stored in the same repositories as source code; see Common Version Control. However, this is no longer considered a best practice. Source and package management are now viewed as two separate things; see Source versus Package Repos. Source repositories should be reserved for text-based artifacts whose differences can be made visible in a human-understandable way. Package repositories in contrast are for binary artifacts that can be deployed.
Package repositories also can serve as a proxy to the external world of downloadable software. That is, they are a cache, an intermediate store of the software provided by various external or “upstream” sources. For example, developers may be told to download the approved Ruby on Rails® version from the local package repository, rather than going to get the latest version, which may not be suitable for the environment.
Package repositories, furthermore, are used to enable collaboration between teams working on large systems. Teams can check in their built components into the package repository for other teams to download. This is more efficient than everyone always building all parts of the application from the source repository.
The boundary between source and package is not hard and fast, however. We sometimes see binary files in source repositories, such as images used in an application. Also, when interpreted languages (such as JavaScript™) are “packaged”, they still appear in the package as text files, perhaps compressed or otherwise incorporated into some larger containing structure.
While in earlier times, systems would be compiled for the target platform (e.g., compiled in a development environment, and then re-compiled for subsequent environments such as quality assurance and production) the trend today is decisively towards immutability. With the standardization brought by container-based architecture, current preference increasingly is to compile once into an immutable artifact that is deployed unchanged to all environments, with any necessary differences managed by environment-specific configuration such as source-managed text artifacts and shared secrets repositories.
Deployment Management
Version control is an important part of the overall concept of configuration management. But configuration management also covers the matter of how artifacts under version control are combined with other IT resources (such as virtual machines) to deliver services. Configuration Management and its Components elaborates on Types of Version Control to depict the relationships.
Resources in version control in general are not yet active in any value-adding sense. In order for them to deliver experiences, they must be combined with computing resources: servers (physical or virtual), storage, networking, and the rest, whether owned by the organization or leased as cloud services. The process of doing so is called deployment. Version control manages the state of the artifacts; meanwhile, deployment management (as another configuration management practice) manages the combination of those artifacts with the needed resources for value delivery.
Imperative and Declarative Approaches
Before we turned to source control, we looked at a simple script that changed the configuration of a computer. It did so in an imperative fashion. Imperative and declarative are two important terms from computer science.
In an imperative approach, the computer is told specifically how we want to accomplish a task; for example:
-
Create a directory
-
Create some files
-
Create another directory
-
Create more files
Many traditional programming languages take an imperative approach. A script such as our iac.sh example is executed line by line; i.e., it is imperative.
In configuring infrastructure, scripting is in general considered “imperative”, but state-of-the-art infrastructure automation frameworks are built using a “declarative”, policy-based approach, in which the object is to define the desired end state of the resource, not the steps needed to get there. With such an approach, instead of defining a set of steps, we simply define the proper configuration as a target, saying (in essence) that “this computer should always have a directory structure thus; do what you need to do to make it so and keep it this way”.
Declarative approaches are used to ensure that the proper versions of software are always present on a system and that configurations such as Internet ports and security settings do not vary from the intended specification.
This is a complex topic, and there are advantages and disadvantages to each approach [Burgess 2016].
Evidence of Notability
Andrew Clay Shafer, credited as one of the originators of DevOps, stated: “In software development, version control is the foundation of every other Agile technical practice. Without version control, there is no build, no test-driven development, no continuous integration” [Allspaw & Robbins 2010]. It is one of the four foundational areas of Agile, according to the Agile Alliance [Agile Alliance 2016].
Limitations
Older platforms and approaches relied on direct command line intervention and (in the 1990s and 2000s) on GUI-based configuration tools. Organizations still relying on these approaches may struggle to adopt the principles discussed here.
Competency Category “Configuration Management and Infrastructure as Code” Example Competencies
-
Develop a simple Infrastructure as Code definition for a configured server
-
Demonstrate the ability to install, configure, and use a source control tool
-
Demonstrate the ability to install, configure, and use a package manager
-
Develop a complex Infrastructure as Code definition for a cluster of servers, optionally including load balancing and failover
Related Topics