DevOps Technical Practices
Description
Consider this inquiry by Mary and Tom Poppendieck:
The implicit goal is that the organization should be able to change and deploy one line of code, from idea to production in under an hour, and in fact, might want to do so on an ongoing basis. There is deep Lean/Agile theory behind this objective; a theory developed in reaction to the pattern of massive software failures that characterized IT in the first 50 years of its existence. (This document discusses systems theory, including the concept of feedback, in Context II and other aspects of Agile theory, including the ideas of Lean Product Development, in Contexts II and III.)
Achieving this goal is feasible but requires new approaches. Various practitioners have explored this problem, with great success. Key initial milestones included:
-
The establishment of “test-driven development” as a key best practice in creating software [Beck & Andres 2004]
-
Duvall’s book Continuous Integration [Duvall 2007]
-
John Allspaw and Paul Hammond’s seminal “10 Deploys a Day” presentation describing technical practices at Flickr [Allspaw & Hammond 2009]
-
Jez Humble and David Farley’s Continuous Delivery [Humble & Farley 2010]
-
The publication of The Phoenix Project [Kim et al. 2013]
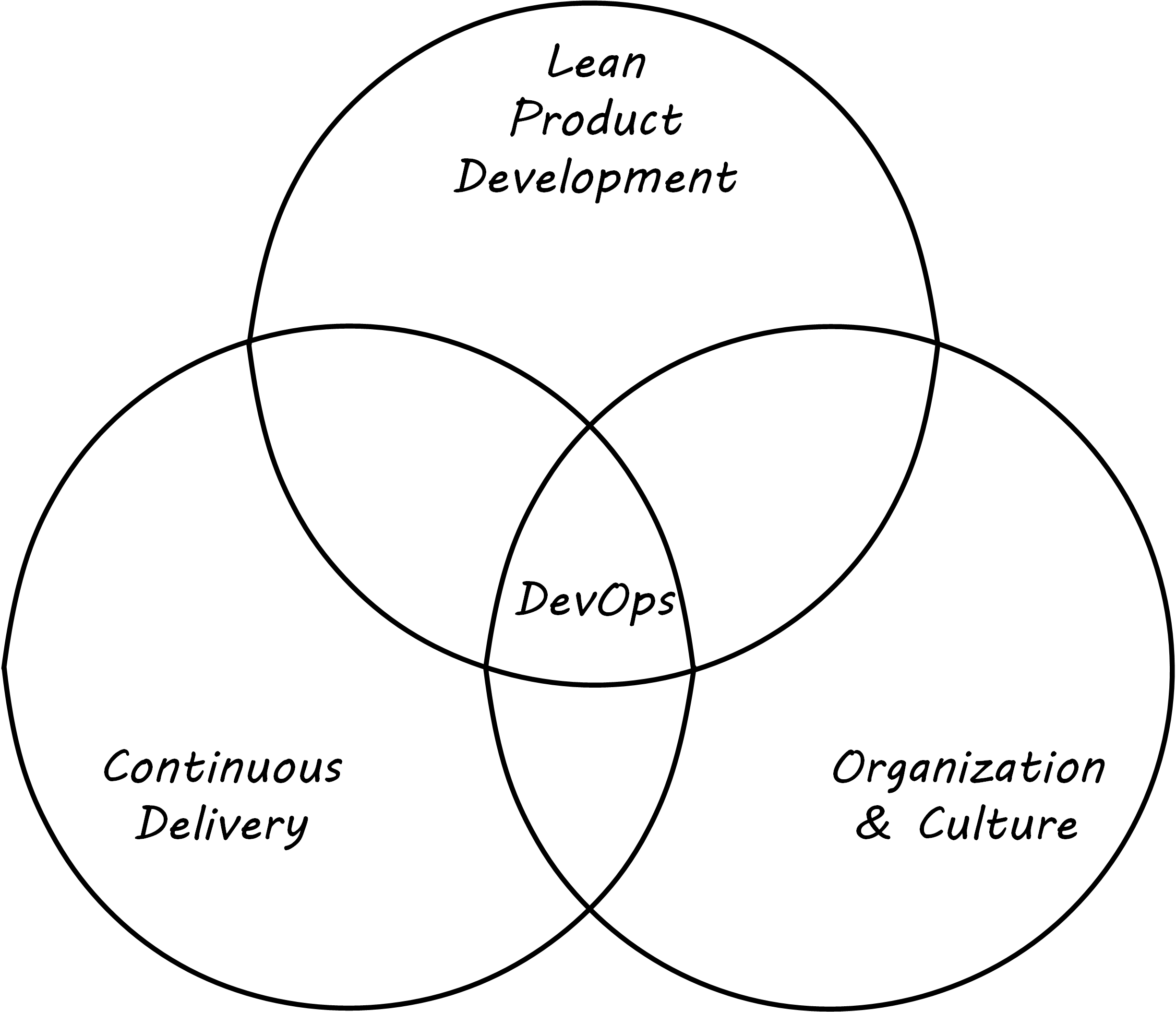
Defining DevOps
“DevOps” is a broad term, encompassing product management, continuous delivery, organization structure, team behaviors, and culture; see DevOps Definition. Some of these topics will not be covered until Contexts II and III in this document. At an execution level, the fundamental goal of moving smaller changes more quickly through the pipeline is a common theme. Other guiding principles include: “If it hurts, do it more frequently”. (This is in part a response to the poor practice, or antipattern, of deferring integration testing and deployment until those tasks are so big as to be unmanageable.) There is a great deal written on the topic of DevOps currently; Humble & Farley 2010 is recommended as an introduction. Let us go into a little detail on some essential Agile/DevOps practices:
-
Test-driven development
-
Ongoing refactoring
-
Continuous integration
-
Continuous deployment
Continuous Delivery Pipeline
The infrastructure Competency Area suggests that the Digital Practitioner may need to select:
-
Development stack (language, framework, and associated enablers such as database and application server)
-
Cloud provider that supports the chosen stack
-
Version control
-
Deployment capability
The assumption is that the Digital Practitioner is going to start immediately with a continuous delivery pipeline.
What is meant by a continuous delivery pipeline? A Simple Continuous Delivery Toolchain presents a simplified, starting overview.
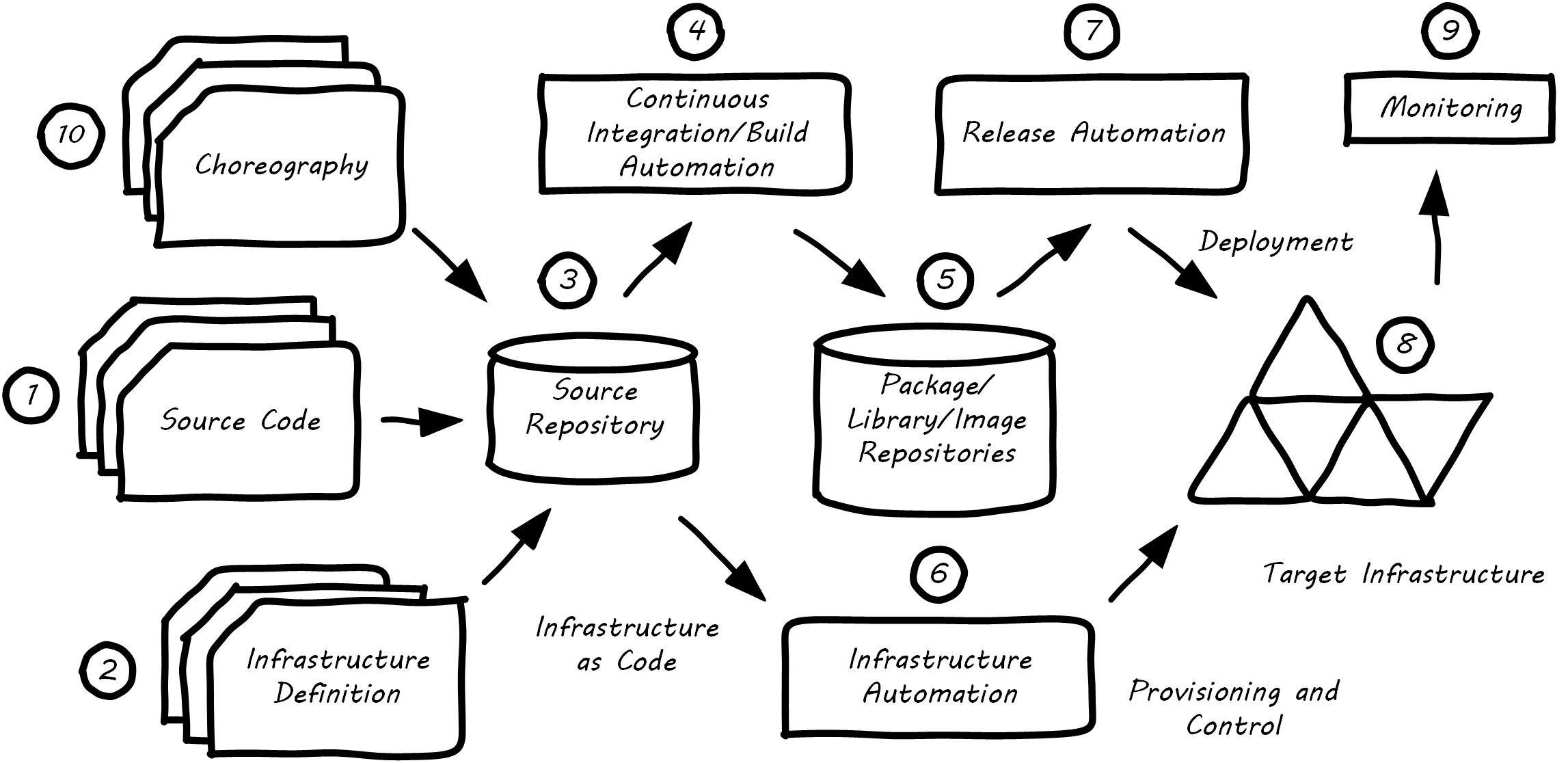
First, some potential for value is identified. It is refined through product management techniques into a feature – some specific set of functionality that when complete will enable the value proposition (i.e., as a moment of truth).
-
The feature is expressed as some set of IT work, today usually in small increments lasting between one and four weeks (this of course varies). Software development commences; e.g., the creation of Java components by developers who first write tests, and then write code that satisfies the test.
-
More or less simultaneously, the infrastructure configuration is also refined, also “as code”.
-
The source repository contains both functional and infrastructure artifacts (text-based).
-
When the repository detects the new “check-in”, it contacts the build choreography manager, which launches a dedicated environment to build and test the new code. The environment is configured using “Infrastructure as Code” techniques; in this way, it can be created automatically and quickly.
-
If the code passes all tests, the compiled and built binary executables may then be “checked in” to a package management repository.
-
Infrastructure choreography may be invoked at various points to provision and manage compute, storage, and networking resources (on-premise or cloud-based).
-
Release automation deploys immutable binary packages to target infrastructure.
-
Examples of such infrastructure may include quality assurance, user acceptance, and production environments.
-
The production system is monitored for availability and performance.
-
An emerging practice is to manage the end-to-end flow of all of the above activities as “choreography”, providing a comprehensive traceability of configuration and deployment activities across the pipeline.
Test Automation and Test-Driven Development
Testing software and systems is a critically important part of digital product development. The earliest concepts of waterfall development called for it explicitly, and “software tester” as a role and “software quality assurance” as a practice have long histories. Evolutionary approaches to software have a potential major issue with software testing:
As a consequence of the introduction of new bugs, program maintenance requires far more system testing per statement written than any other programming. Theoretically, after each fix one must run the entire bank of test cases previously run against the system, to ensure that it has not been damaged in an obscure way. In practice, such regression testing must indeed approximate this theoretical ideal, and it is very costly. [Brooks 1975]
This issue was and is well known to thought leaders in Agile software development. The key response has been the concept of automated testing so that any change in the software can be immediately validated before more development along those lines continues. One pioneering tool was JUnit:
The reason JUnit is important … is that the presence of this tiny tool has been essential to a fundamental shift for many programmers. A shift where testing has moved to a front and central part of programming. People have advocated it before, but JUnit made it happen more than anything else. [Meszaros 2007]
From the reality that regression testing was “very costly” (as stated by Brooks in the above quote), the emergence of tools like JUnit (coupled with increasing computer power and availability) changed the face of software development, allowing the ongoing evolution of software systems in ways not previously possible.
In test-driven development, the idea essence is to write code that tests itself, and in fact to write the test before writing any code. This is done through the creation of test harnesses and the tight association of tests with requirements. The logical culmination of test-driven development was expressed by Kent Beck in eXtreme Programming: write the test first [Beck & Andres 2004]. Thus:
-
Given a “user story” (i.e., system intent), figure out a test that will demonstrate its successful implementation
-
Write this test using the established testing framework
-
Write the code that fulfills the test
Employing test-driven development completely and correctly requires thought and experience. But it has emerged as a practice in the largest-scale systems in the world. Google runs many millions of automated tests daily [Whittaker et al. 2012]. It has even been successfully employed in hardware development [Gruver et al. 2012].
Refactoring and Technical Debt
Test-driven development enables the next major practice, that of refactoring. Refactoring is how technical debt is addressed. What is technical debt? Technical debt is a term coined by Ward Cunningham and is now defined by Wikipedia as: “the eventual consequences of poor system design, software architecture, or software development within a codebase. The debt can be thought of as work that needs to be done before a particular job can be considered complete or proper. If the debt is not repaid, then it will keep on accumulating interest, making it hard to implement changes later on. Analogous to monetary debt, technical debt is not necessarily a bad thing, and sometimes technical debt is required to move projects forward”.
Test-driven development ensures that the system’s functionality remains consistent, while refactoring provides a means to address technical debt as part of ongoing development activities. Prioritizing the relative investment of repaying technical debt versus developing new functionality will be examined in future sections.
Technical debt is covered further here.
Continuous Integration
As systems engineering approaches transform to cloud and Infrastructure as Code, a large and increasing percentage of IT work takes the form of altering text files and tracking their versions. This was covered in the discussion of configuration management with artifacts such as scripts being created to drive the provisioning and configuring of computing resources. Approaches which encourage ongoing development and evolution are increasingly recognized as less risky since systems do not respond well to big “batches” of change. An important concept is that of “continuous integration”, popularized by Paul Duvall in his book of the same name [Duvall 2007].
In order to understand why continuous integration is important, it is necessary to discuss further the concept of source control and how it is employed in real-world settings. Imagine Mary has been working for some time with her partner Aparna in their startup (or on a small team) and they have three code modules; see File B being Worked on by Two People. Mary is writing the web front end (File A), Aparna is writing the administrative tools and reporting (File C), and they both partner on the data access layer (File B). The conflict, of course, arises on File B that they both need to work on. A and C are mostly independent of each other, but changes to any part of B can have an impact on both their modules.
If changes are frequently needed to B, and yet they cannot split it into logically separate modules, they have a problem; they cannot both work on the same file at the same time. They are each concerned that the other does not introduce changes into B that “break” the code in their own modules A and C.
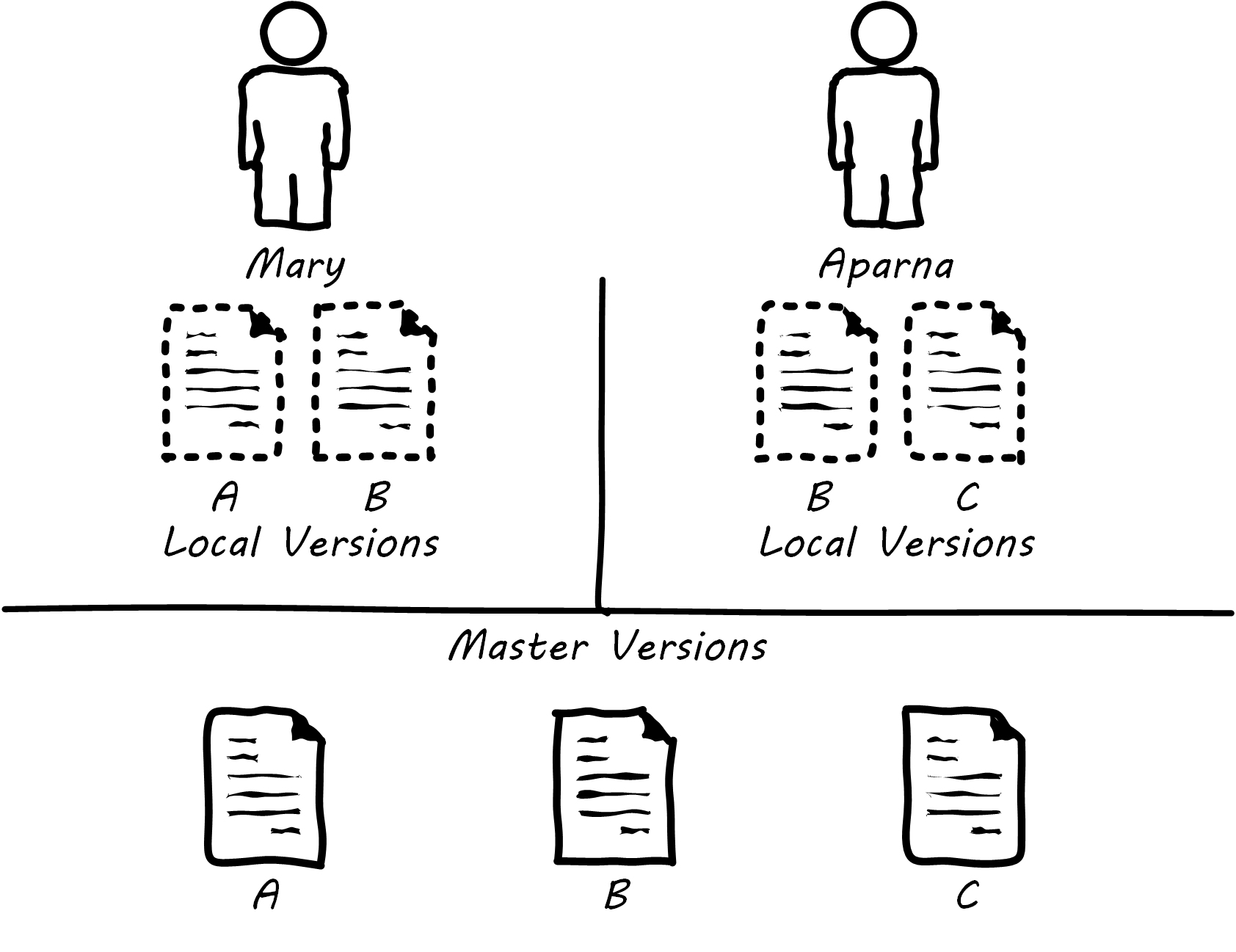
In smaller environments, or under older practices, perhaps there is no conflict, or perhaps they can agree to take turns. But even if they are taking turns, Mary still needs to test her code in A to make sure it has not been broken by changes Aparna made in B. And what if they really both need to work on B (see File B being Worked on by Two People) at the same time?
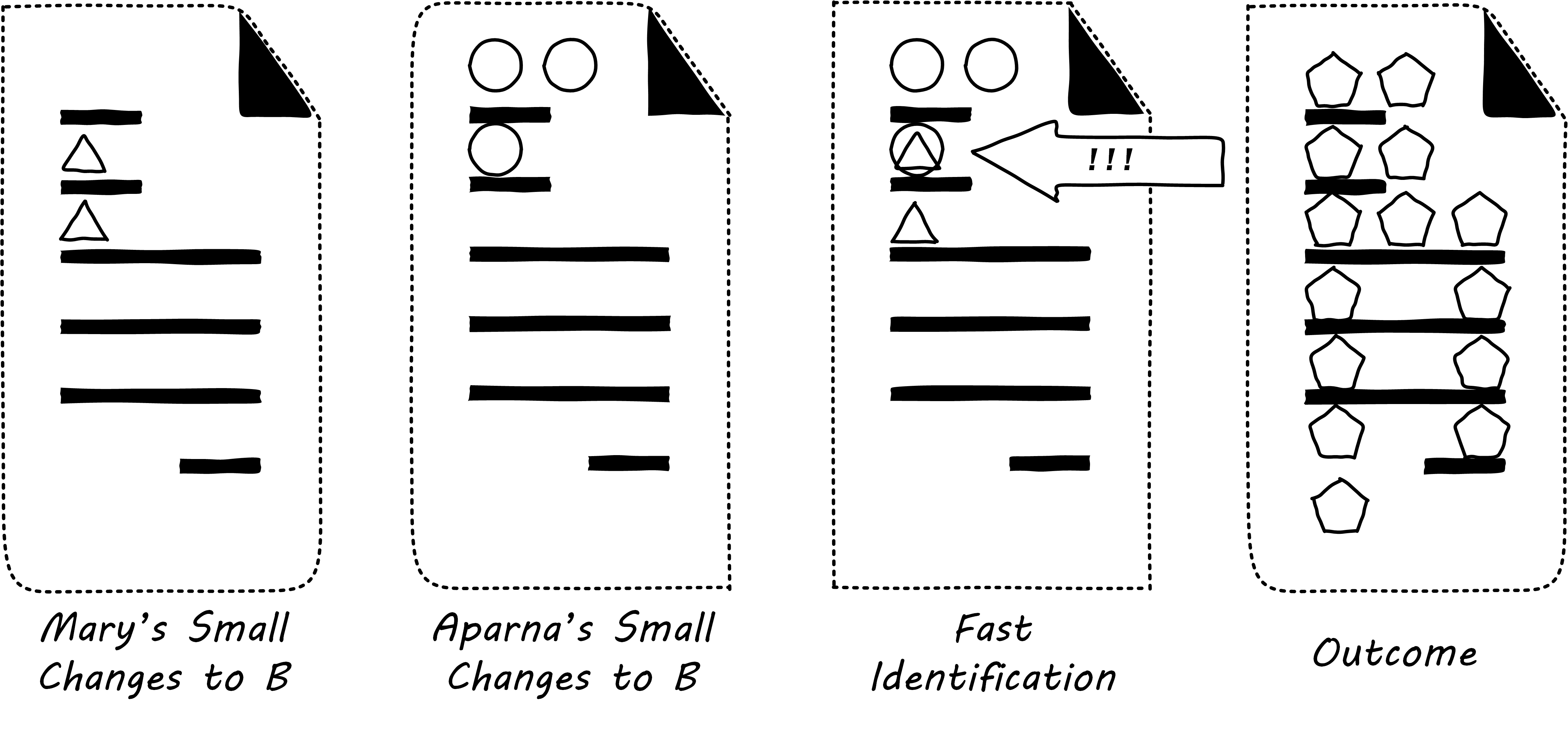
Given that they have version control in place, each of them works on a “local” copy of the file. That way, they can move ahead on their local workstations. But when the time comes to combine both of their work, they may find themselves in “merge hell”; see Merge Hell. They may have chosen very different approaches to solving the same problem, and code may need massive revision to settle on one codebase. For example, in the accompanying illustration, Mary’s changes to B are represented by triangles and Aparna’s are represented by circles. They each had a local version on their workstation for far too long, without talking to each other.
The diagrams represent the changes graphically; of course, with real code, the different graphics represent different development approaches each person took. For example, Mary had certain needs for how errors were handled, while Aparna had different needs.
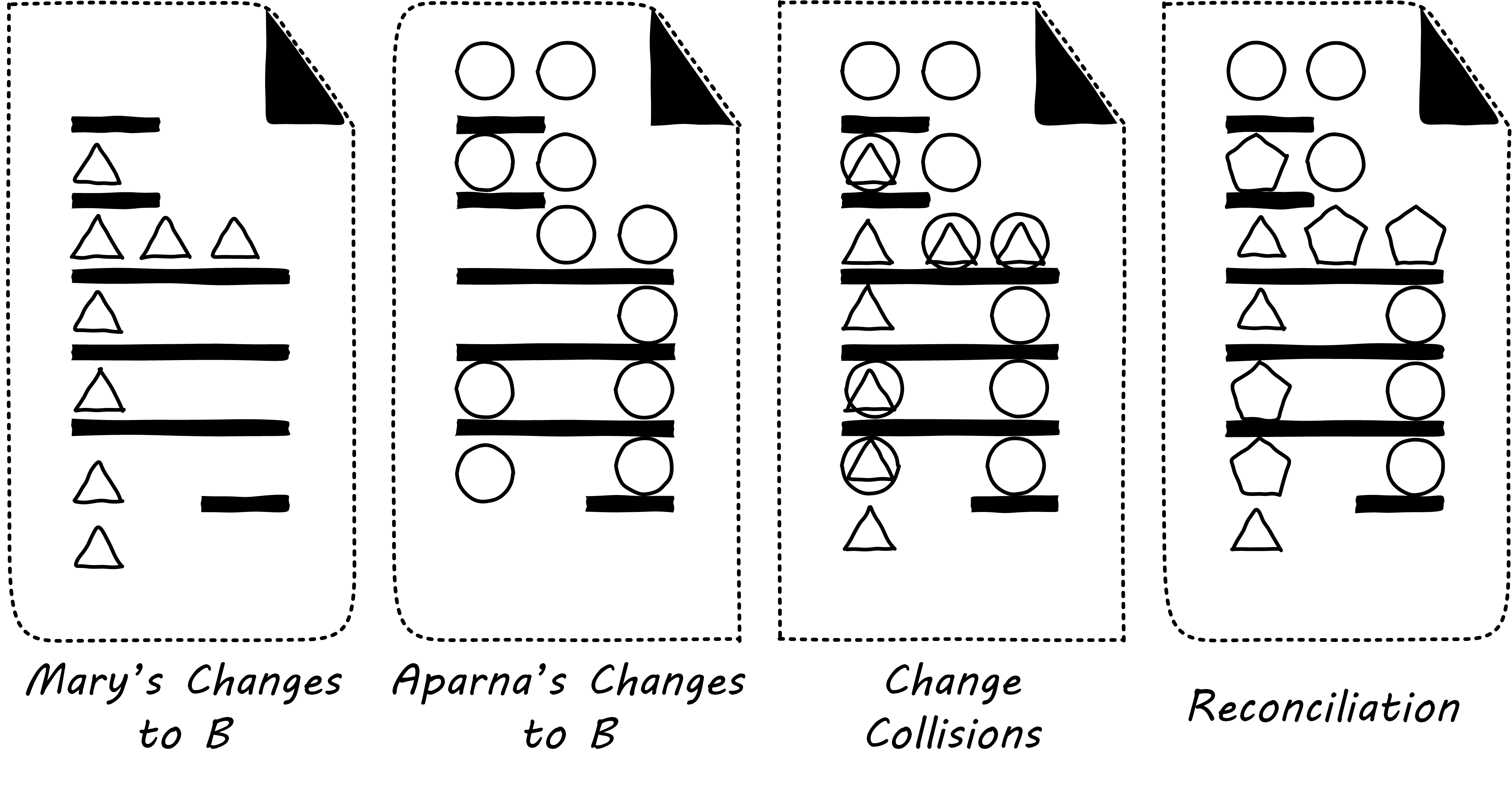
In Merge Hell, where triangles and circles overlap, Mary and Aparna painstakingly have to go through and put in a consolidated error handling approach, so that the code supports both of their needs. The problem, of course, is there are now three ways errors are being handled in the code. This is not good, but they did not have time to go back and fix all the cases. This is a classic example of technical debt.
Suppose instead that they had been checking in every day. They can identify the first collision quickly (see Catching Errors Quickly is Valuable), and have a conversation about what the best error handling approach is. This saves them both the rework of fixing the collisions, and the technical debt they might have otherwise accepted:
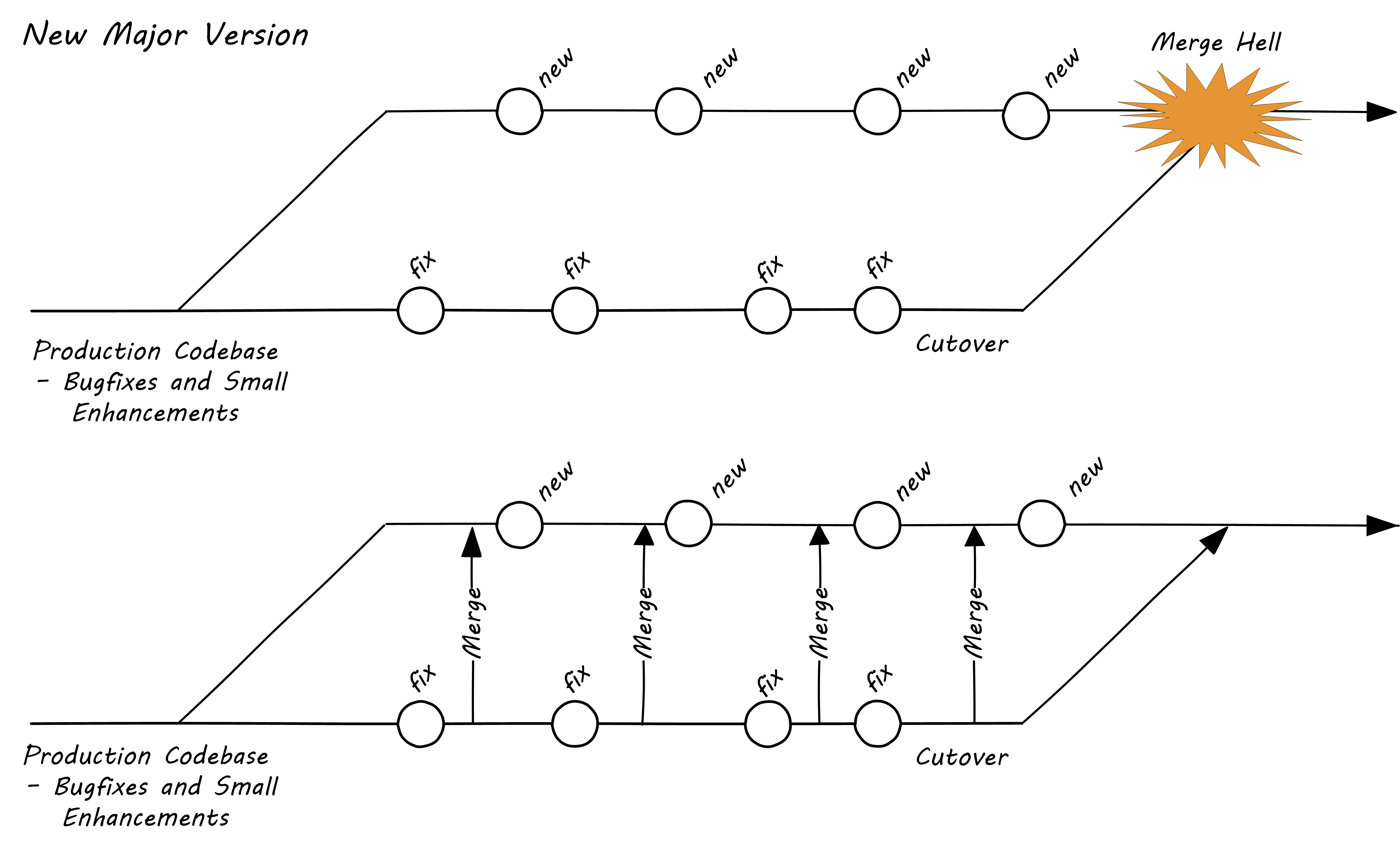
These problems have driven the evolution of software configuration management for decades. In previous methods, to develop a new release, the code would be copied into a very long-lived “branch” (a version of the code to receive independent enhancement). Ongoing “maintenance” fixes of the existing codebase would also continue, and the two codebases would inevitably diverge. Switching over to the “new” codebase might mean that once-fixed bugs (bugs that had been addressed by maintenance activities) would show up again, and, logically, this would not be acceptable. So, when the newer development was complete, it would need to be merged back into the older line of code, and this was rarely if ever easy (again, “merge hell”). In a worst-case scenario, the new development might have to be redone.
Enter continuous integration; see Big Bang versus Continuous Integration. As presented in Duvall 2007, the key practices (note similarities to the pipeline discussion) include:
-
Developers run private builds including their automated tests before committing to source control
-
Developers check in to source control at least daily
-
Distributed version control systems such as Git are especially popular, although older centralized products are starting to adopt some of their functionality
-
Integration builds happen several times a day or more on a separate, dedicated machine
-
-
100% of tests must pass for each build, and fixing failed builds is the highest priority
-
A package or similar executable artifact is produced for functional testing
-
A defined package repository exists as a definitive location for the build output
Rather than locking a file so that only one person can work on it at a time, it has been found that the best approach is to allow developers to actually make multiple copies of such a file or file set and work on them simultaneously.
This is the principle of continuous integration at work. If the developers are continually pulling each other’s work into their own working copies, and continually testing that nothing has broken, then distributed development can take place. So, for a developer, the day’s work might be as follows:
8:00am: Check out files from master source repository to a local branch on the workstation. Because files are not committed unless they pass all tests, the code is clean. The developer selects or is assigned a user story (requirement) that they will now develop.
8:30am: The developer defines a test and starts developing the code to fulfill it.
10:00am: The developer is close to wrapping up the first requirement. They check the source repository. Their partner has checked in some new code, so they pull it down to their local repository. They run all the automated tests and nothing breaks, so all is good.
10:30am: They complete their first update of the day; it passes all tests on the local workstation. They commit it to the master repository. The master repository is continually monitored by the build server, which takes the code created and deploys it, along with all necessary configurations, to a dedicated build server (which might be just a virtual machine or transient container). All tests pass there (the test defined as indicating success for the module, as well as a host of older tests that are routinely run whenever the code is updated).
11:00am: Their partner pulls these changes into their working directory. Unfortunately, some changes made conflict with some work the partner is doing. They briefly consult and figure out a mutually-acceptable approach.
Controlling simultaneous changes to a common file is only one benefit of continuous integration. When software is developed by teams, even if each team has its own artifacts, the system often fails to “come together” for higher-order testing to confirm that all the parts are working correctly together. Discrepancies are often found in the interfaces between components; when Component A calls Component B, it may receive output it did not expect and processing halts. Continuous integration ensures that such issues are caught early.
Continuous Integration Choreography
DevOps and continuous delivery call for automating everything that can be automated. This goal led to the creation of continuous integration managers such as Hudson, Jenkins, Travis CI, and Bamboo. Build managers may control any or all of the following steps:
-
Detecting changes in version control repositories and building software in response
-
Alternately, building software on a fixed (e.g., nightly) schedule
-
Compiling source code and linking it to libraries
-
Executing automated tests
-
Combining compiled artifacts with other resources into installable packages
-
Registering new and updated packages in the package management repository, for deployment into downstream environments
-
In some cases, driving deployment into downstream environments, including production (this can be done directly by the build manager, or through the build manager sending a message to a deployment management tool)
Build managers play a critical, central role in the modern, automated pipeline and will likely be a center of attention for the new Digital Practitioner in their career.
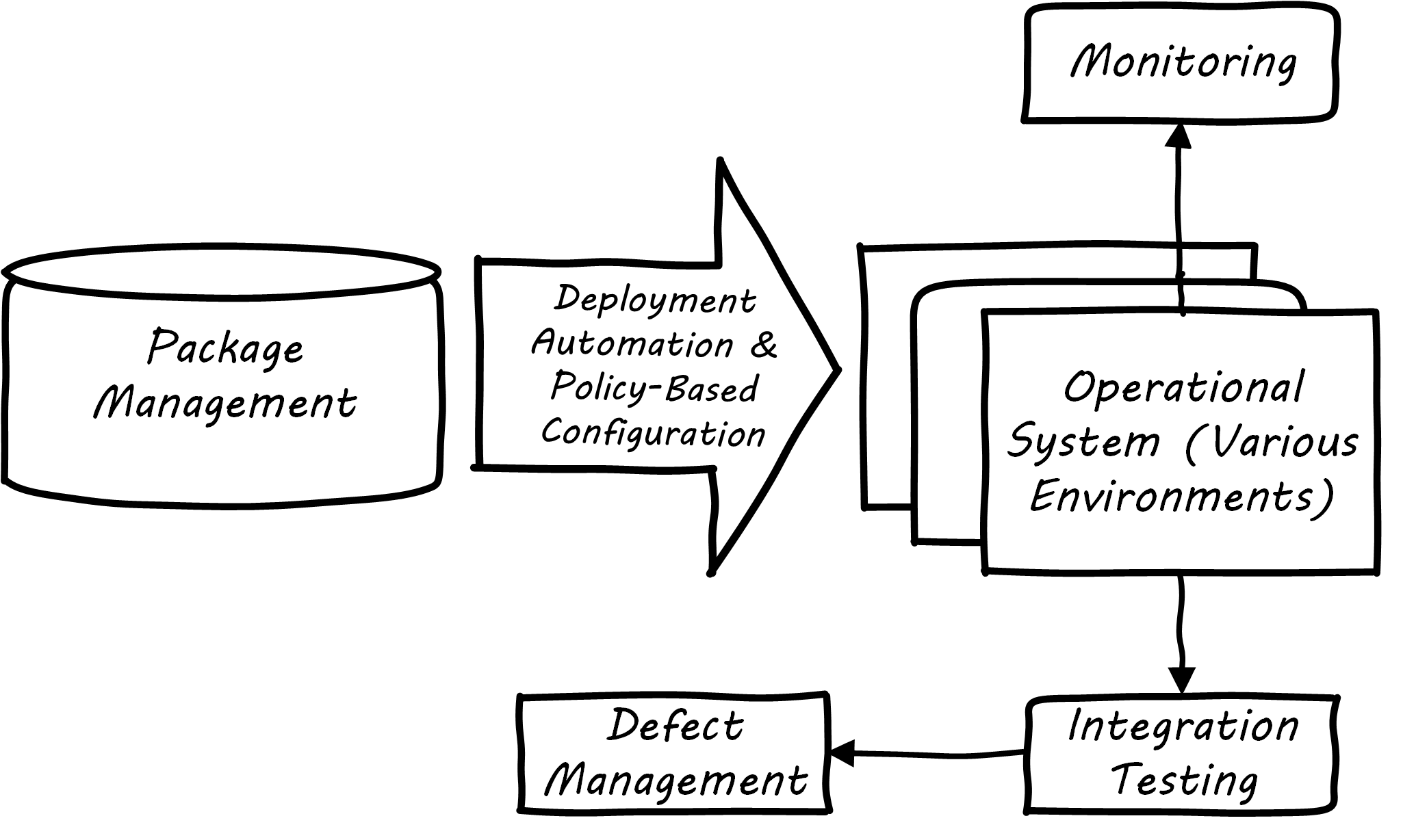
Continuous Delivery
Once the software is compiled and built, the executable files that can be installed and run operationally should be checked into a package manager. At that point, the last mile steps can be taken, and the now tested and built software can be deployed to pre-production or production environments; see Deployment. The software can undergo usability testing, load testing, integration testing, and so forth. Once those tests are passed, it can be deployed to production.
Moving new code into production has always been a risky procedure. Changing a running system always entails some uncertainty. However, the practice of Infrastructure as Code coupled with increased virtualization has reduced the risk. Often, a rolling release strategy is employed so that code is deployed to small sets of servers while other servers continue to service the load. This requires careful design to allow the new and old code to co-exist at least for a brief time.
This is important so that the versions of software used in production are well controlled and consistent. The package manager can then be associated with some kind of deploy tool that keeps track of what versions are associated with which infrastructure.
Timing varies by organization. Some strive for true “continuous deployment”, in which the new code flows seamlessly from developer commit through build, test, package, and deploy. Others put gates in between the developer and check-in to mainline, or source-to-build, or package-to-deploy so that some human governance remains in the toolchain. This document goes into more detail on these topics in the section on digital operations.
The Concept of “Release”
Release management, and the concept of a “release”, are among the most important and widely seen concepts in all forms of digital management. Regardless of working in a cutting-edge Agile startup with two people or one of the largest banks with a portfolio of thousands of applications, releases for coordination and communication are likely being used.
What is a “release”? Betz defined it this way in other work: “A significant evolution in an IT service, often based on new systems development, coordinated with affected services and stakeholders”. Release management’s role is to “coordinate the assembly of IT functionality into a coherent whole and deliver this package into a state in which the customer is getting the intended value” [Betz 2011a].
Evidence of Notability
DevOps has not yet been fully recognized for its importance in academic guidance or peer-reviewed literature. Nevertheless, its influence is broad and notable. Significant publications include Allspaw & Hammond 2009, Duvall 2007, Forsgren et al. 2018, Humble & Molesky 2011, Kim et al. 2013, and Kim et al. 2016. Large international conferences (notably the DevOps Enterprise Summit) are dedicated to the event, as well as many smaller local events under the banner of “DevOpsDays”.
Limitations
Like Agile, DevOps is primarily valuable in the development of new digital functionality. It has less relevance for organizations that choose to purchase digital functionality; e.g., as SaaS offerings. While it includes the fragment “Ops”, it does not cover the full range of operational topics covered in the Operations Competency Area, such as help desk and field services.
Related Topics