Operations-Driven Product Demand
Description
Designing complex systems that can scale effectively and be operated efficiently is a challenging topic. Many insights have been developed by the large-scale public-facing Internet sites, such as Google, Facebook, Netflix, and others.
A reasonable person might question why systems design questions are appearing here in this Competency Area on operations. We have discussed certain essential factors for system scalability previously: cloud, Infrastructure as Code, version control, and continuous delivery. These are all necessary, but not sufficient to scaling digital systems. Once a system starts to encounter real load, further attention must go to how it runs, as opposed to what it does. It is not easy to know when to focus on scalability. If product discovery is not on target, the system will never get the level of use that requires scalability. Insisting that the digital product has a state-of-the-art and scalable design might be wasteful if the team is still searching for an MVP (in Lean Startup terms). Of course, if you are doing systems engineering and building a “cog”, not growing a “flower", you may need to be thinking about scalability earlier.
Eventually, scale matters. Cloud computing abstracts many concerns, but as your IT service’s usage increases, you will inevitably find that technical details such as storage and network architecture increasingly matter. What often happens is that the system goes through various prototypes until something with market value is found and, at that point, as use starts to scale up, the team scrambles for a more robust approach. The implementation decisions made by the Digital Practitioner and their service providers may become inefficient for the particular “workload” the product represents. The brief technical write-up, Latency Numbers Every Programmer Should Know is recommended.
There are dozens of books and articles discussing many aspects of how to scale systems. In this section, we will discuss two important principles: the CAP principle and the AKF scaling cube. If you are interested in this topic in depth, consult the references in this Competency Area.
The CAP Principle
Scaling digital systems used to imply acquiring faster and more powerful hardware and software. If a 4-core server with 8 gigabytes of RAM is not enough, get a 32-core server with 256 gigabytes of RAM (and upgrade your database software accordingly, for millions of dollars more). This kind of scaling is termed “vertical” scaling. However, web-scale companies such as Facebook and Google determined that this would not work indefinitely. Vertical scaling in an infinite capacity is not physically (or financially) possible. Instead, these companies began to experiment aggressively with using large numbers of inexpensive commodity computers.
The advantage to vertical scaling is that all your data can reside on one server, with fast and reliable access. As soon as you start to split your data across servers, you run into the practical implications of the CAP principle; see CAP Principle.
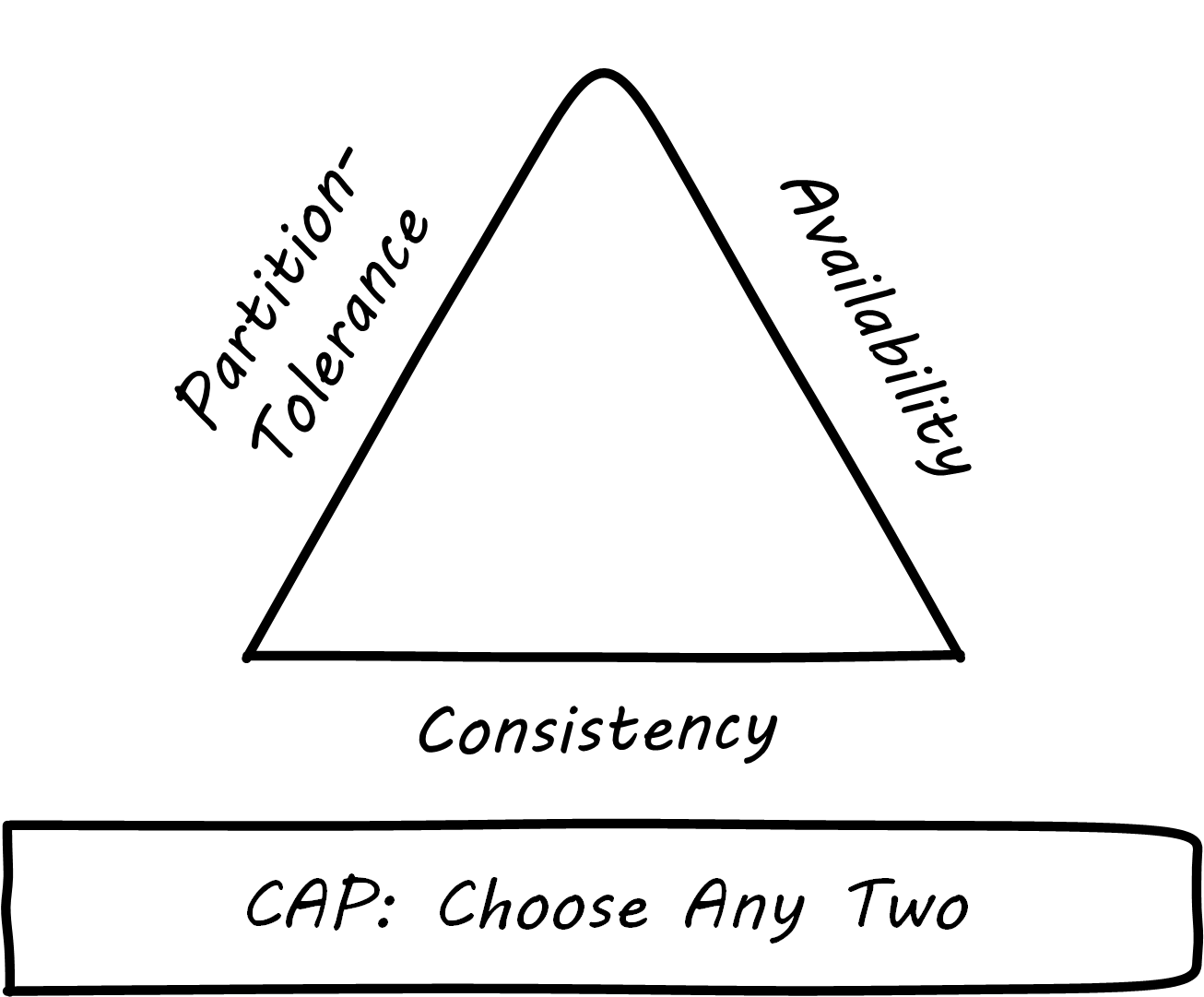
CAP stands for:
-
Consistency
-
Availability
-
Partition-tolerance
The CAP principle (or theorem) states that it is not possible to build a distributed system that guarantees all three [Fox & Brewer 1999]. What does this mean? First, let us define our terms.
Consistency means that all the servers (or “nodes”) in the system see the same data at the same time. If an update is being processed, no node will see it before any other. This is often termed a transactional guarantee, and it is the sort of processing relational databases excel at.
For example, if you change your flight, and your seat opens up, a consistent reservation application will show the free seat simultaneously to anyone who inquires, even if the reservation information is replicated across two or more geographically distant nodes. If the seat is reserved, no node will show it available, even if it takes some time for the information to replicate across the nodes. The system will simply not show anyone any data until it can show everyone the correct data.
Availability means what it implies: that the system is available to provide data on request. If we have many nodes with the same data on them, this can improve availability, since if one is down, the user can still reach others.
Partition-tolerance is the ability of the distributed system to handle communications outages. If we have two nodes, both expected to have the same data, and the network stops communicating between them, they will not be able to send updates to each other. In that case, there are two choices: either stop providing services to all users of the system (failure of availability) or accept that the data may not be the same across the nodes (failure of consistency).
In the earlier years of computing, the preference was for strong consistency, and vendors such as Oracle® profited greatly by building database software that could guarantee it when properly configured. Such systems could be consistent and available, but could not tolerate network outages – if the network was down, the system, or at least a portion of it, would also be down.
Companies such as Google and Facebook took the alternative approach. They said: “We will accept inconsistency in the data so that our systems are always available”. Clearly, for a social media site such as Facebook, a posting does not need to be everywhere at once before it can be shown at all. To verify this, simply post to a social media site using your computer. Do you see the post on your phone, or your friend’s, as soon as you submit it on your computer? No, although it is fast, you can see some delay. This shows that the site is not strictly consistent; a strictly consistent system would always show the same data across all the accessing devices.
The challenge with accepting inconsistency is how to do so. Eventually, the system needs to become consistent, and if conflicting updates are made they need to be resolved. Scalable systems in general favor availability and partition-tolerance as principles, and therefore must take explicit steps to restore consistency when it fails. The approach taken to partitioning the system into replicas is critical to managing eventual consistency, which brings us to the AKF scaling cube.
For further discussion, see Limoncelli et al 2014, Section 1.5.
The AKF Scaling Cube
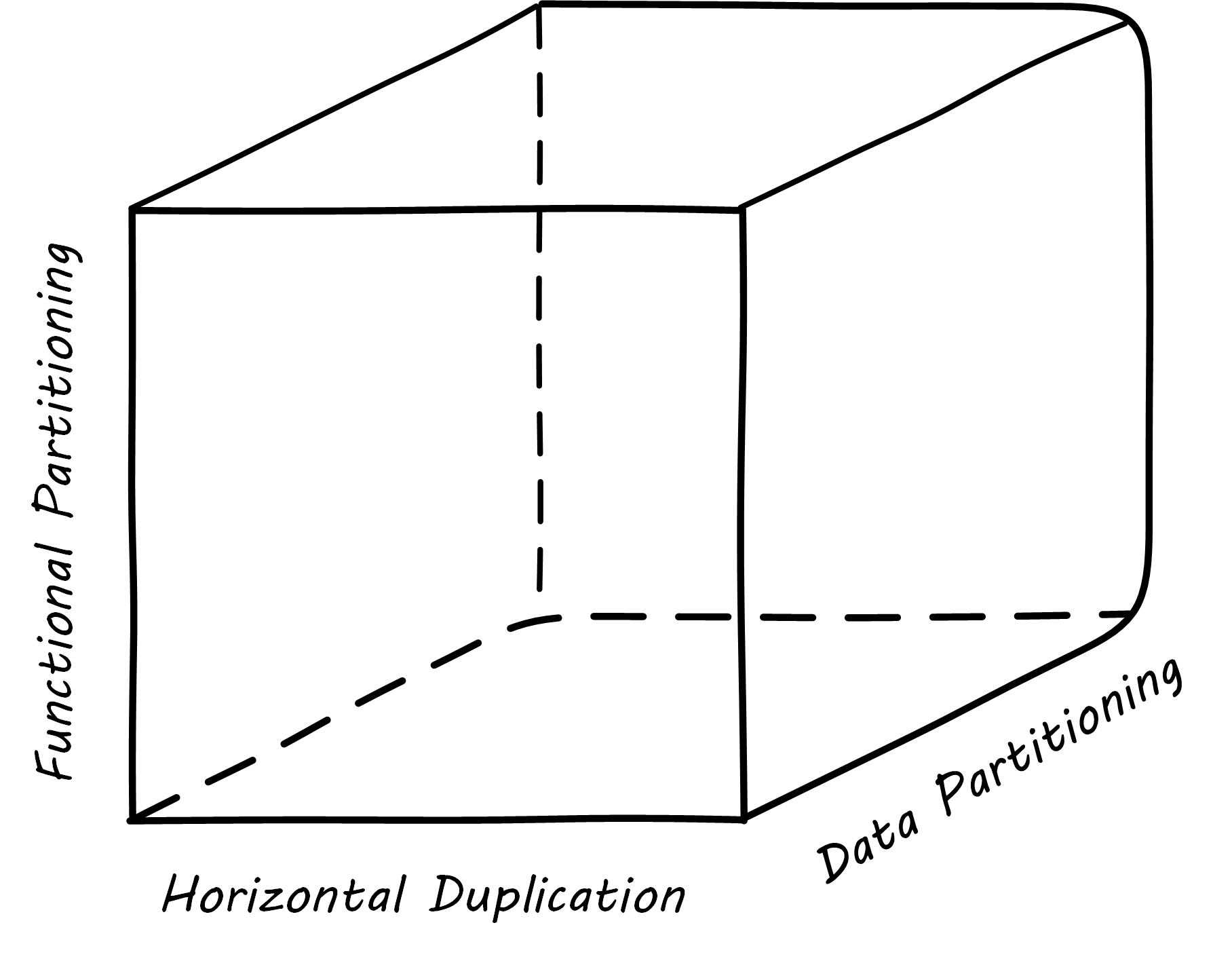
Another powerful tool for thinking about scaling systems is the AKF scaling cube; see AKF Scaling Cube (similar to Abbott & Fisher 2015). AKF stands for Abbott, Keeven, and Fisher, authors of The Art of Scalability [Abbott & Fisher 2015]. The AKF cube is a visual representation of the three basic options for scaling a system:
-
Replicate the complete system (x-axis)
-
Split the system functionally into smaller layers or components (y-axis)
-
Split the system’s data (z-axis)
A complete system replica is similar to the Point of Sale (POS) terminals in a retailer. Each is a self-contained system with all the data it needs to handle typical transactions. POS terminals do not depend on each other; therefore you can keep increasing the capacity of your store’s checkout lines by simply adding more of them.
Functional splitting is when you separate out different features or components. To continue the retail analogy, this is like a department store; you view and buy electronics, or clothes, in those specific departments. The store “scales” by adding departments, which are self-contained in general; however, in order to get a complete outfit, you may need to visit several departments. In terms of systems, separating web and database servers is commonly seen – this is a component separation. E-commerce sites often separate “show” (product search and display) from “buy” (shopping cart and online checkout); this is a feature separation. Complex distributed systems may have large numbers of features and components, which are all orchestrated together into one common web or smartphone app experience.
Data splitting (sometimes termed “sharding”) is the concept of “partitioning” from the CAP discussion, above. For example, consider a conference with check-in stations divided by alphabet range; for example:
-
A-H register here
-
I-Q register here
-
R-Z register here
This is a good example of splitting by data. In terms of digital systems, we might split data by region; customers in Minnesota might go to the Kansas City data center, while customers in New Jersey might go to a North Carolina data center. Obviously, the system needs to handle situations where people are traveling or move.
There are many ways to implement and combine the three axes of the AKF scaling cube to meet the CAP constraints. With further study of scalability, you will encounter discussions of:
-
Load balancing architectures and algorithms
-
Caching
-
Reverse proxies
-
Hardware redundancy
-
Designing systems for continuous availability during upgrades
and much more. For further information, see Abbott & Fisher 2015 and Limoncelli et al. 2014.
Evidence of Notability
Operational insights result in requirements for products to be changed. This is an important feedback loop from the operations to the development phase, and a major theme in IT operations management literature; see, for example, Limoncelli et al. 2014, “Part I Design: Building It”.
Limitations
Operational demand focuses on how the system runs, not what it does. Both, however, are valid concerns for product management.
Related Topics