Data Information and Artificial Intelligence (AI)
The rapidly dropping cost of memory and storage combined with the rise in popularity of big data has motivated enterprises to collect an increasing amount of data. Some enterprises collected vast amounts of data without a clear purpose. That data is stored in data lakes as data scientists try to figure out what to do with it.
For example, in 2016 Capital One® reported gathering over 450GB per day in raw data, which drove costs up. As much as 80% of gathered data is meaningless or unused, and key data is sometimes missing [Paulchell 2016].
In a batch architecture, time to insight is too long. It can take several days just to get the right data in the right place, process it, and generate actionable insights:
-
Application generates data that is captured into operational data storage
-
Data is moved daily to a data platform that runs an Extract, Transform, Load (ETL) to clean, transform, and enrich data
-
Once processed, data is loaded into data warehouses, data marts, or Online Analytical Processing (OLAP) cubes
-
Analytics tools programmed with languages, such as R®, SAS® software, or Python®, are used in conjunction with visualization tools
-
Reporting tools such as R, SAS software, SQL, or Tableau® are used to analyze data and find insights
-
Actions based on insights are implemented
The batch model is prevalent even after the big data revolution. Traditional Business Intelligence (BI) technology is still used by many enterprises to manage financial, risk, or commercial data. Migrating from legacy tools and technologies is difficult and often requires the rewriting of legacy code. For example, a large bank that uses Teradata™ to run risk models had to re-implement them because the algorithms were dependent on the Database Management System (DBMS) data schema.
Data Streaming Architectures
The shift to an architecture capable of handling large amounts of data coming at high speed, processed continuously, and acted upon in real time makes it possible to access data when and where you need it. Technologies such as Apache Spark™ or Flink® enable the shift toward real-time data streaming. Analyzing the evolution of the technology landscape is beyond the scope of this document; it evolves so rapidly. The requirements of well-architected streaming solutions are:
-
To scale up and down gracefully
-
To auto heal, in case major spikes break the system
-
Throttling, to protect downstream systems that could not handle the spike
-
Fault tolerance, to improve resilience
-
Modularity of the solutions building blocks, to facilitate reuse and evolution
-
Monitoring friendliness, to facilitate business and IT operations
Coupling Data Streaming with AI
Enterprises create innovative services by coupling real-time data streaming with AI; for example, the Capital One Auto Navigator® App [Groenfeldt 2018].
The new service idea started with a survey of 1,000 nationally representative US adults to learn how they approach the car shopping process.
Customers can use their smartphone to recognize a car, even in motion, that caught their attention. AI is used to classify the car and help find similar ones that are selling in nearby markets. The user can save the information to prepare for a visit to a dealership.
Once customers have identified cars they like, the app (see Auto Navigator) lets them personalize financing to simulate payments specific to the car they want. Pre-qualification has no impact on their credit score. When they are ready to purchase the car they have all the information needed, spend less time at the dealership, and get a better deal.
“I was very impressed with how easy my buying experience was. I had my financing ahead of time and was able to make my time at the dealership so much faster.” (Testimony from the Capital One Site)
Now that the power of combining great customer research with fast data and AI technology to develop innovative products has been described, the Data Architecture impacts can be analyzed.
Most fundamental data management principles and best practices remain valid even though some need to be updated to account for business and technology evolution. The emergence of new data engineering patterns requires a fundamental shift in the way data systems are architected.
Data Model and Reality
The correspondence between things inside the information system and things in the real world still matters. Audit Control Objectives shows:
-
The correspondence between data and the real world
-
Data quality criteria are mostly technology-neutral, though implementation is likely to leverage technology
| Objective | Control |
|---|---|
All transactions are recorded |
Procedures should be in place to avoid the omission of operations in the account books |
Each transaction is: |
|
Real |
Do not record fictitious transactions and do not record the same transaction twice |
Properly valued |
Verify that the amounts posted are correct |
Accounted for in the correct period |
Verify that the business rules that determine in which period a transaction should be posted are applied |
Correctly allocated |
Verify that transactions are aggregated into the right accounts |
Data is only a model of reality, it is not reality. Depending on the context, the same territory (reality) can be represented using different maps (models).
The Monolithic Data Model
“When files get integrated into a database serving multiple applications, that ambiguity-resolving mechanism is lost.” [Kent 2012]
To illustrate his point, the author uses the example of the concept of a “part”. In a warehouse context each part has a part number and occurs in various quantities at various warehouses. In a quality control context, part means one physical object; each part being subjected to certain tests, and the test data maintained in a database separately for each part.
Part Modeling represents the database that would serve the inventory management and quality control applications. In addition, a data model has been created to represent the part concept in each context.
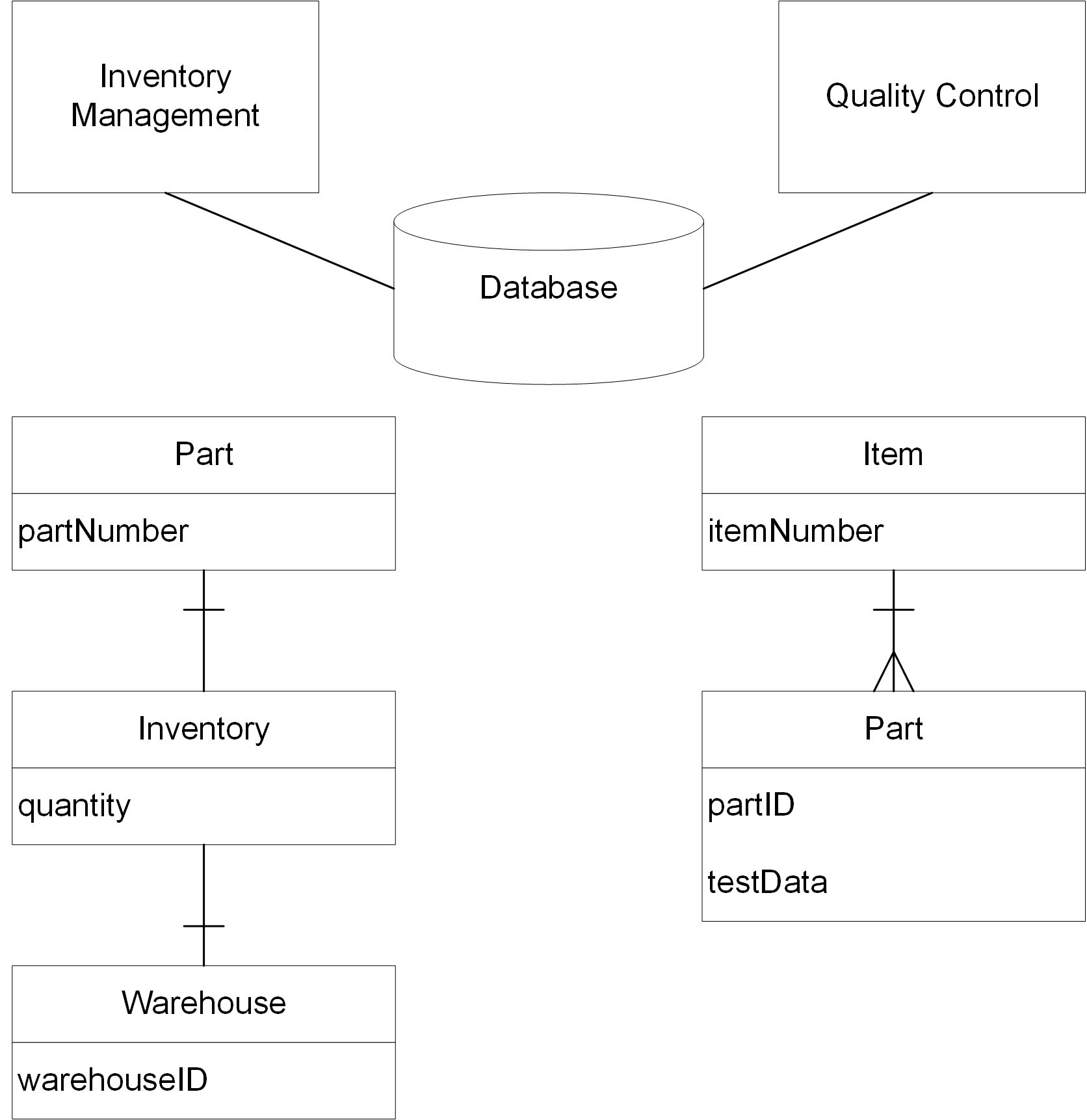
The word “part” has a specific meaning in each context. In designing a shared database, the model would be unified at the expense of the vocabulary used in one of the contexts. As “Part” and “Item” mean the same thing, there are two options:
-
Rename “Item” “Part” in the “Quality Control” context and find another name for “Part” in this context
-
Rename “Part” “Item” in the “Inventory Management” context and find another name for “Item” in this context
The shared database would start using a language of its own, which could lead to communication problems and errors.
“Total unification of the domain model for a large system will not be feasible or cost-effective.” [Evans 2003]
The example of Monolithic Data Architecture illustrates the total data unification that is common in financial systems. This type of “monster” project often fails because it is impractical to fold all source system data models into one generic data model. This approach would create a number of problems; for example:
-
Specifying translation rules between domain-specific data models and the common data model is difficult because the cognitive load is too high for data modelers
-
It is unrealistic to replicate source system business rules into the data monolith; for example, lease accounting rules require an estimate of when a leased car is likely to be returned
-
When a defect occurs, it is difficult to backtrack to the root causes
-
Back and forth data structure translation is costly and error-prone
-
When new products or new regulations are introduced, mastering all the resulting side effects on the monolithic Data Architecture is challenging
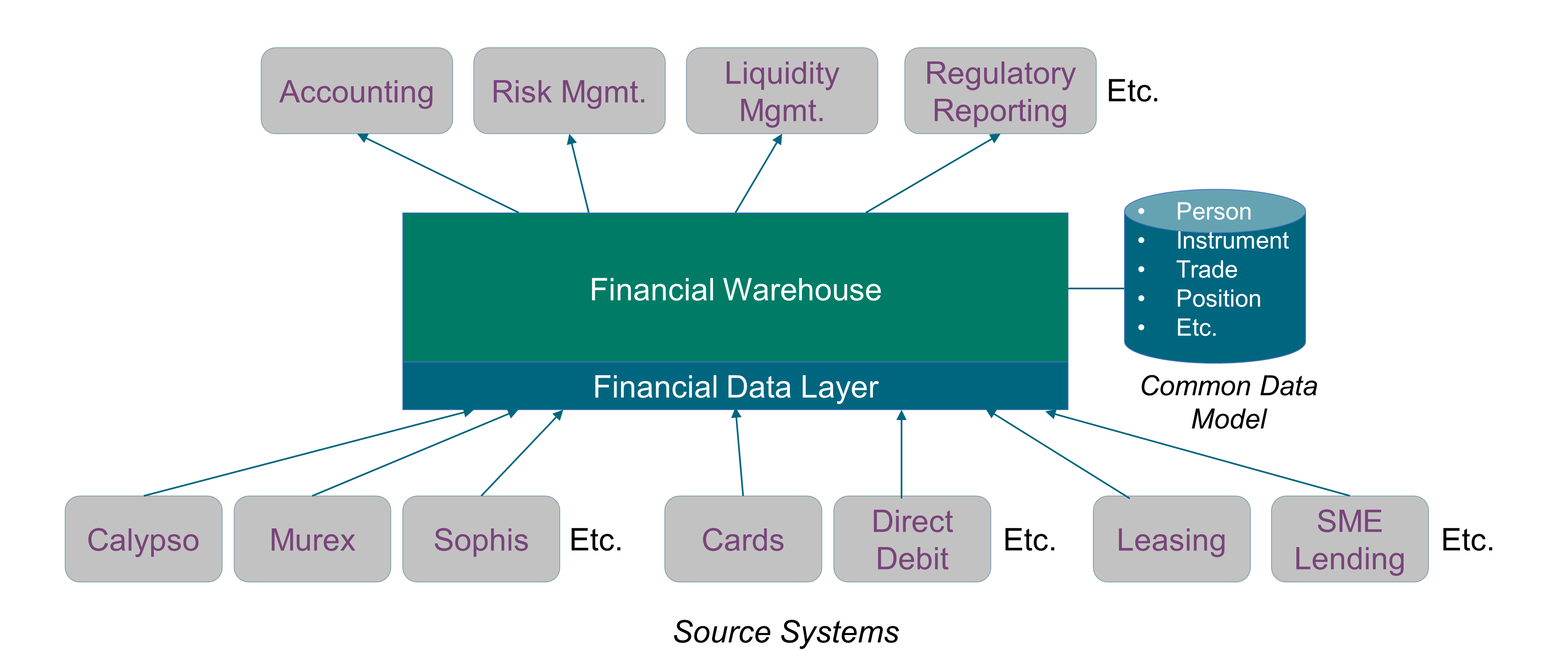
Moving Away from Monolithic Data Architectures
In a post on Martin Fowler’s blog, Zhamak Dehghani shows how it is possible to adapt and apply the learnings of the past decade in building distributed architectures at scale to the domain of data; and introduces a new enterprise Data Architecture that she calls “data mesh” [Dehghani 2019].
Zhamak argues that instead of flowing the data from domains into a centrally owned data lake or platform, domains need to host and serve their domain datasets in an easily consumable way. This requires shifting our thinking from a push and ingest, traditionally through ETLs and more recently through event streams, to a serve and pull model across all domains.
The monolithic Data Architecture is replaced by a modular one, and composed of:
-
Bounded contexts aligned with data source domains, such as fixed-income trading or consumer lending
-
Bounded contexts aligned with consumption domains, such as accounting or liquidity
Business facts are represented by domain events that capture what happened in reality.
A product-thinking mindset can help provide a better experience to data consumers. For example, source domains can provide easily consumable historical snapshots of the source domain datasets, aggregated over a time interval that closely reflects the interval of change for their domain.
Machine Learning Pipelines
There is a lot of data manipulation and transformation in Machine Learning (ML) systems. ML pipelines industrialize data manipulation and transformation. They are composed of data processing components that run in a certain order. Data components usually run asynchronously. Each component pulls in a large amount of data, processes it, and puts results in other data stores.
Each data component is fairly self-contained and communicates with other data components via data stores. If a component breaks down, downstream components can often continue to run normally by using the last output from the broken component. This makes the architecture quite robust unless a broken component goes unnoticed for some time. This is why proper monitoring is required to avoid data going stale.
TensorFlow Extended (TFX) is an end-to-end platform for deploying production ML pipelines. TensorFlow Pipeline, which is copied from [TFX User Guide], gives an example of an ML pipeline.
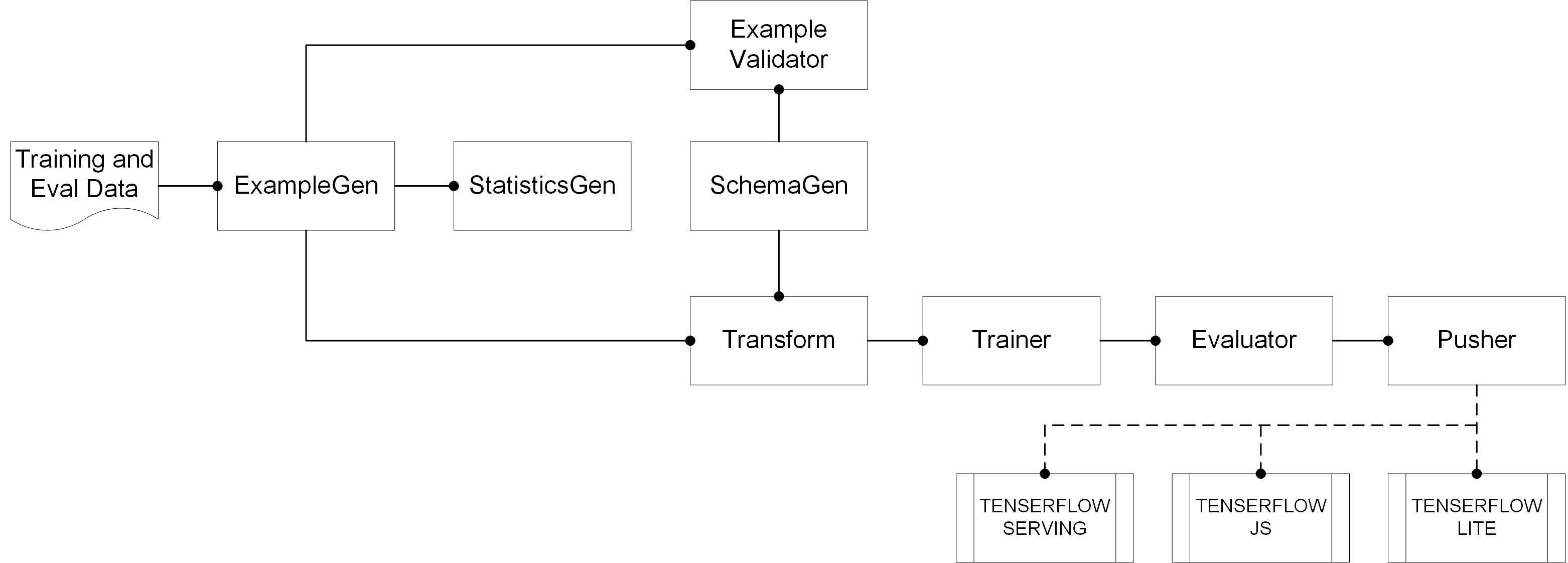
It includes a set of data components:
-
ExampleGen is the initial input component of a pipeline that ingests and optionally splits the input dataset
-
StatisticsGen calculates statistics for the dataset
-
SchemaGen examines the statistics and creates a data schema
-
ExampleValidator looks for anomalies and missing values in the dataset
-
Transform performs feature engineering on the dataset
-
Trainer trains the model
-
Evaluator performs deep analysis of the training results and helps to validate exported models, ensuring that they are “good enough” to be pushed to production
-
Pusher deploys the model on a serving infrastructure
TFX provides several Python packages that are the libraries used to create pipeline components.
Deep Learning for Mobile
Mobile devices are now capable of leveraging the ever-increasing power of AI to learn user behavior and preferences, enhance photographs, carry out full-fledged conversations, and more [Kent 2012].
Leveraging AI on mobile devices can improve user experience [Singh 2020]:
-
Personalization adapts the device and the app to a user’s habits and their unique profile instead of generic profile-oriented applications
-
Virtual assistants are able to interpret human speech using Natural Language Understanding (NLU) and generally respond via synthesized voices
-
Facial recognition identifies or verifies a face or understands a facial expression from digital images and videos
-
AI-powered cameras recognize, understand, and enhance scenes and photographs
-
Predictive text help users compose texts and send emails much faster than before
The most popular apps now use AI to enhance user experience.
A Few Concluding Words
The shift toward real-time data streaming and modular Data Architecture changes the way enterprise data systems are designed and developed. When combined with AI, it is possible to create innovative products that deliver superior customer experience, such as the one illustrated by Coupling Data Streaming with AI.