Creating and Evolving Agile Models
Important in any kind of modeling endeavor, and certainly also in an Agile context, is the evolution of your models. Some may be created as one-shot views intended to be used for a small audience and then thrown away, but many models have a longer life. In this chapter, we want to address this lifecycle.
Creating Models in an Agile Way
First and foremost, the modeling process itself is something that should be done using the same Agile principles that you use for developing software. That means that the creation of models is itself an iterative process that starts small and gradually extends models with content needed for specific purposes. This process should move in lock-step with the evolution of what these models describe.
Some models are used as input for the design of some piece of software (or business process, product, etc.) and therefore need to be "one step ahead". As we know from Agile ways of working, you want to postpone decision-making to the latest possible moment, when you have the best available information. That also holds true for models in an Agile context. They are developed with a "just in time" mindset; for example, to provide context for developers in the next few sprints, for portfolio managers to decide on priorities of the next epics, etc. This also means that the further ahead a model aims to look, the less concrete it will be. In ArchiMate terms, this translates into:
-
Models that only provide the longer-term, high-level intent in motivation and strategy elements (see also Which ArchiMate Layers to Focus On?)
-
Medium-term and medium-level models with more concrete details; for example, to express main features as services, and to define concepts like an Architectural Runway
-
Short-term, detailed models that are used; for example, to describe application components and their services and interfaces for developers who need to connect to them
All these models should be created by and with those who are directly involved, so the intent and ideas are captured at the source.
A second category of models are those that are created to comprehend the pre-existing, current situation. Most development is "brownfield" and you need to understand this context. Models are helpful to get a handle on the complexity of such a current situation. For example, complicated communication patterns between microservices are very difficult to understand by just looking at the code. A model can clarify this.
Now, having to create those models of the current situation from scratch might be an inordinate effort. Ideally, those models would have been created and maintained by previous teams, but that is often not the case. The second-best option is to automate some of the model creation with more and more of the tools that exist to discover, for example, software components communicating on your network and that information can be used to build up a bottom-up view of the current state. The automated creation of, for example, ArchiMate models of the IT infrastructure based on information from those discovery tools, often linked to modern Configuration Management Data Base (CMDB) software, is how state-of-the-art teams work nowadays. At a business level, process mining tools can be used to discover the business processes of an organization. And we can expect more and more data analysis and techniques based on Artificial Intelligence (AI) that help gain these kinds of insights and build up your models.
However, what you cannot reconstruct from just looking at the world out there is the intent behind what you see. What were the key design decisions and trade-offs? What alternatives were rejected and why? Who were the main stakeholders and what were their drivers? This is the main reason that you do need to document what you design and not just try to reverse-engineer after the fact. This is again an argument for modeling intentional architecture in (ArchiMate) models.
That leads us to the third type of models, those that are intended to document what has been created after the fact so that others understand it. Those models are typically "one step behind" in the development and realization process. Agile methods recommend that you document late (but not too late!) so you capture what has actually been realized and you can incorporate relevant learning experiences; for example, feedback from customers, peer reviews, or retrospectives. Moreover, the solution as realized may deviate from the solution as designed, and these differences are important to be understood and discussed.
Leverage Existing Methods and Practices
Agile (and especially Agile at scale) often comes with methods (such as domain-driven design or event storming) or even emerging documentation practices (like documentation or model as code approaches such as Simon Brown’s C4 Model[1]). These methods and practices should be leveraged and used as starting points for architecture viewpoints based on the ArchiMate Specification. Doing so will help to establish the ArchiMate notation as a standard for everyone and will also make it easier to share information between team members and architects.
For example, a typical business-level data model (Business-Level Data Model) can serve as an input for a workshop whose goal is to clarify the product domain model (Product Domain Model), which can then be added to the ArchiMate model.
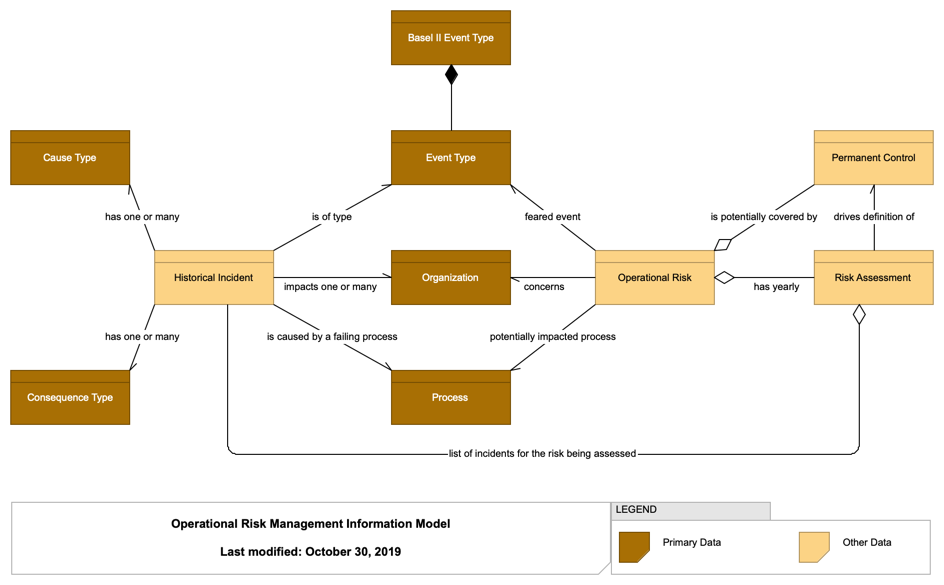
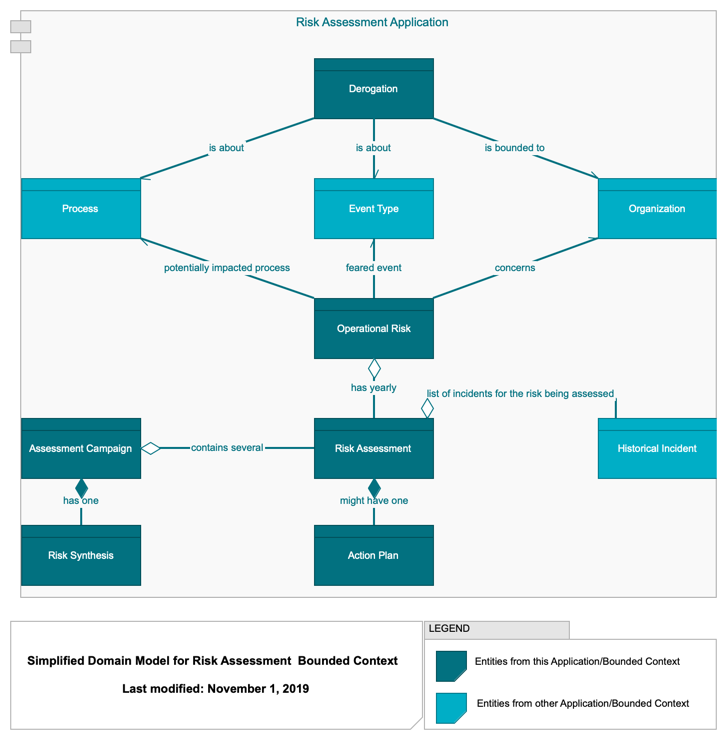
In the same vein, event storming sessions come with their own conventions, mostly based on the color of the physical sticky notes used. Such conventions can be used in the model to keep track of the information gathered during the workshop, as shown in Event Storming Model.
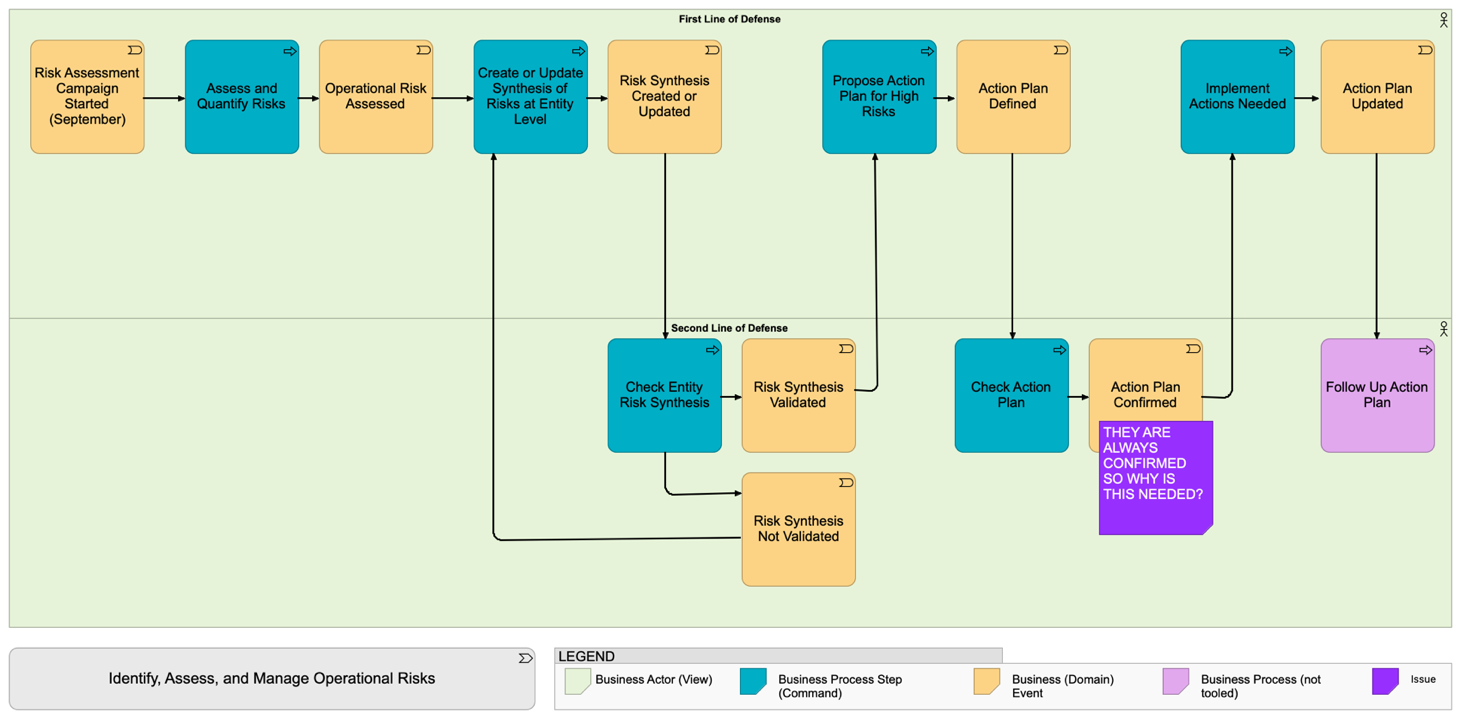
The overall advantage of creating architecture viewpoints based on existing methods and practices is that people will be used to them and can reuse them in their own documents. This is usually a very good sign when some of your architecture views appear in someone else’s presentation or in the wiki maintained by a team, as it will help show the value of architecture work and will provide you with more feedback. To help this but also to avoid potential misunderstandings, you should make sure that some basic information is always added in your views, such as a title, a legend, and the date of the last update to the view.
Recommended Level of Detail
One of the most commonly asked questions in modeling is: "What is the right level of detail for my models?" However, this is something you cannot simply define up-front. There is no single, "right" level of detail. This strongly depends on the context and objectives of your modeling effort.
Of course, it is not a good idea to document everything in excruciating detail, but models do need to be precise enough for their intended purpose; for example, to help team members understand a solution going forward, DevOps experts to deploy it and resolve issues (also think of integration testing, for instance), and other teams to reuse components and services. Perhaps most importantly, the models need to be available to anyone who needs to make changes in the future without having access to the original designers and builders. This is again where the intent of the architecture is especially important.
Having models that are too detailed often leads to problems in maintaining them, simply because you cannot spare the effort needed to keep everything up-to-date. That in turn leads to models that age quickly, and sometimes results in people turning away from modeling altogether because the models they need to work with are always outdated anyway. This is clearly not the way to go.
So, you should never model more than you are able to maintain (unless it is a one-shot, throwaway model). But how do you then decide on the level of detail?
There are two complementary approaches to take. First of all, arriving at a good, useful level of detail is an iterative process in itself. You can use the Agile process itself to improve this. In a retrospective review you can discuss this and thus finetune your approach. Did you have the right information at the right time? Was the effort needed to create or update your models feasible and worth it? Like any other activity in an Agile approach, modeling should be subject to this continuous improvement of your way of working.
Secondly, you can use a risk-based approach to decide where you need more detail. Most Agile methods are not very specific on this, but some of their predecessors like the Unified Process [10] are explicitly risk-focused and aim to address the most critical risks early on in the process. In line with this, you should create more detailed models for those areas of an architecture or design where the risks are greatest, and include less detail where you can make decisions with some spontaneity and the consequences of an error are limited. For example, deciding on an infrastructural technology is often high-risk because of the cost involved and the need to avoid the time and effort it will take to reverse a decision that turns out to be the wrong choice after all. Other common high-risk areas are health and safety, security, and compliance; for example, Personally Identifiable Information (PII) risk, financial transaction handling, manufacturing process control, etc.
This also implies that your models will not have a single, uniform level of detail. Moreover, even aiming for such a standardized level of detail may lead you to spend effort where it is not really needed and, conversely, to lack the time for those areas where it really counts. So any modeling approach that tries to tell modelers up-front what the "right" level of detail is will most likely result in models that are nearly all at a "wrong" level, either too detailed or not detailed enough.
To make this more concrete, these are some guidelines to help you decide when to add an element to your architecture model:
-
When this element is largely different from the other components (in functionality, type, etc.)
-
When this element will be connected to numerous separate entities
-
When this element is crucial for some desired characteristics (like non-functional requirements such as high availability, performance, etc.)
-
When this element is crucial in the overall orchestration (controlling component)
-
When this element is associated with high-risk or high-cost operations of the enterprise
-
When this element itself or its implementation is costly (or risky)
-
When this element needs to comply with specific regulatory guidelines; e.g., on the use of personal data
As mentioned before, this means that your Agile architecture models will have different levels of detail in different areas, depending on the importance and risk associated with each area. This also lets you spend your modeling efforts where they count most, rather than adding details just because someone has decided for you what the "right" level of detail should be.
Minimum Viable Architecture Model
In the O-AA Standard [1], the concept of an MVA is mentioned. This is the "least/smallest" architecture that provides value. Likewise, an MVA Model (MVAM) can be envisaged: the smallest model that adds relevant value. The guidelines in Leverage Existing Methods and Practices offer a useful starting point to create such an MVAM. As stated, you cannot define up-front how large or small this needs to be; rather its development will be an iterative process, alongside the iterative Agile process itself. Some additional guidelines that may help you in such an effort are:
-
Value will be found at all the Agile levels as described in The Value of Models in Agile Ways of Working – explore these to see what could be helpful in your own context
-
Start from a high-level view (principles, technologies, standards, and patterns) and add detail as and when required, in line with the discussion in Leverage Existing Methods and Practices
-
Experiment with scope breadth and depth to properly partition the architecture and the model; do not overthink it, just try and see what works
-
Avoid highly complex and high-effort designs: "fail fast", there should be a balance between the day-to-day work of the Agile team and the effort of maintaining and evolving this architecture